

|
Adding an Output Operator
An output produces and publishes streams towards a Kafka topic or a data consumer.
Steps:
1. In the Application page, click
![]() and
select Output in
the Add Operator pane .
and
select Output in
the Add Operator pane .
The Output node icon displays in the Graph panel, as well as the properties to be defined in the Operator Settings panel, and the preview of the data in the Schema panel.
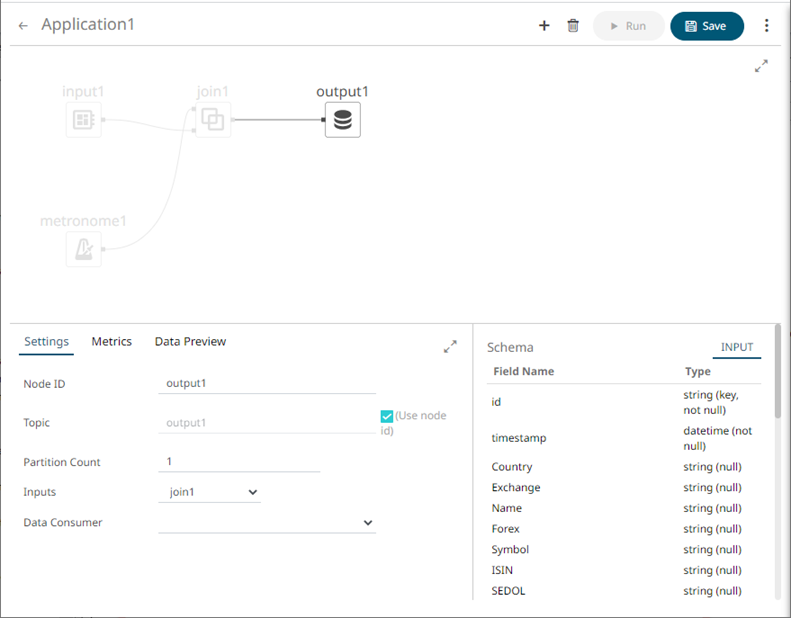
The left (inbound) edge allows you to select the input source or operator.
2. In the Operator Settings panel, define or select the following properties:
|
Property |
Description |
|
Node ID |
The ID of the output operator. |
|
Topic |
The stream of records or output you will be subscribed to. Check the Use Node ID box to use the value entered in the Output ID. Otherwise, uncheck the box and enter a new Topic ID. When adding Topic IDs, ensure they: must be unique across an application must be specified must start with a letter (a to Z) or an underscore. Also, it can only contain letters (a to Z), numbers (0 to 9), and underscores |
|
Partition Count |
Enter the number of partitions for the Kafka topics that will be created for the Output operator. Partitions allow you to parallelize a topic by splitting the data in a particular topic across multiple brokers wherein, each partition can be placed on a separate machine to allow for multiple consumers to read from a topic in parallel. |
|
Inputs |
The left input stream automatically connects to the currently-selected operator. You can select another ID of the operator that will be the source of the data in the Inputs drop-down list. The preview of the data (INPUT) is displayed in the Schema panel. |
|
Data Consumer |
Select the Data Consumer where the output will be produced or published. Currently, the following data consumers are supported: · Text · InfluxDB · Kx kdb+ · Rest |
3. Save the changes.