

|
Creating Elasticsearch 7.x Input Data Source
The Elasticsearch 7.x connector allows you to connect and access data from an Elasticsearch cluster using Java High Level REST Client.
|
NOTE |
· Similar to Elasticsearch 6.x connector but uses Java High Level REST Client. · To enable the Elasticsearch 7.x connector, refer to Elasticsearch Connectors Dependency Installation for more information on how to copy the provided dependency files to the Lib folder. · The Elasticsearch 7.x connector supports Elasticsearch 7.x versions. · Elasticsearch 6.x and Elasticsearch 7.x connectors will not work in a single Panopticon Streams Server instance due to conflicting Elasticsearch API dependencies.
|
Steps:
1. In the New Data Source page, select Input > Elasticsearch 7.x in the Connector drop-down list.
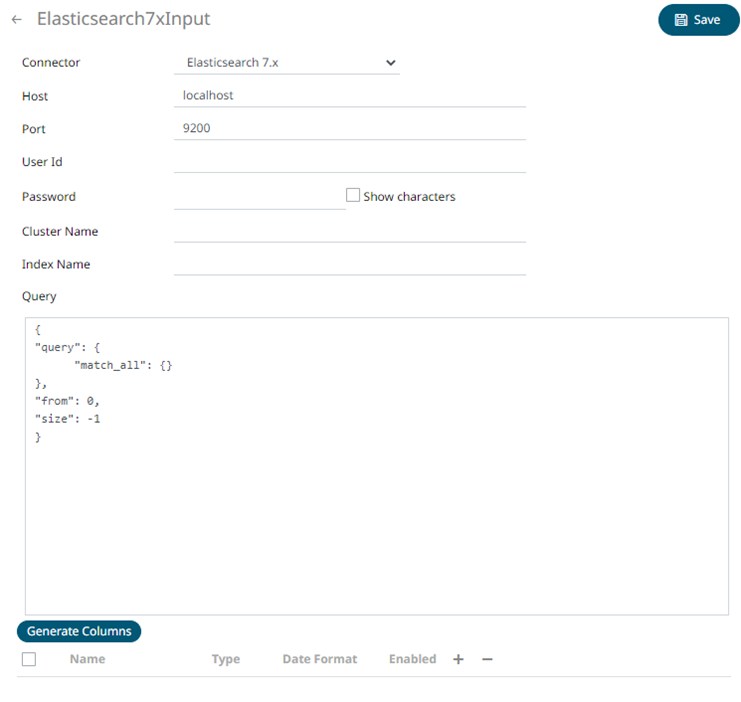
2. Enter the following information:
|
Property |
Description |
|
Host |
The hostname of any node in your Elasticsearch cluster, or localhost for a node on your local machine. |
|
Port |
The port running the Elasticsearch HTTP service (default is 9300). If the port you wish to use is different from the default port, change the value to the correct one. |
|
Cluster Name |
The cluster name that can be used to discover and auto-join nodes. |
|
Index Name |
The Index name in Elasticsearch. This is some type of data organization mechanism that allows partition of data in a certain way. |
3. Enter an optional JSON-encoded request body in the Query box.
4. Click
 . The columns populate the Output
Column section.
. The columns populate the Output
Column section.
5. Click
 to add columns and specify their properties:
to add columns and specify their properties:
|
Property |
Description |
|
Name |
The column name of the source schema. |
|
Type |
The data type of the column. Can be a Text, Numeric, or Time. |
|
Date Format |
The format when the data type is Time. |
|
Enabled |
Determines whether the message field should be processed. |
To delete a column, check its or all the column entries, check the topmost , then click .
4. Click  . The new data source is added in the
Data Sources panel.
. The new data source is added in the
Data Sources panel.