

|
Creating Livy Spark Input Data Source
Livy is an open source REST interface for interacting with Apache Stark. It supports executing snippets of code or programs such as Scala, Python, Java, and R in a Spark context that runs locally or in Apache Hadoop YARN.
The Livy Spark connector allows you to run these codes and fetch the data in Panopticon Streams Server.
Steps:
1. In the New Data Source page, select Input > LivySpark in the Connector drop-down list.
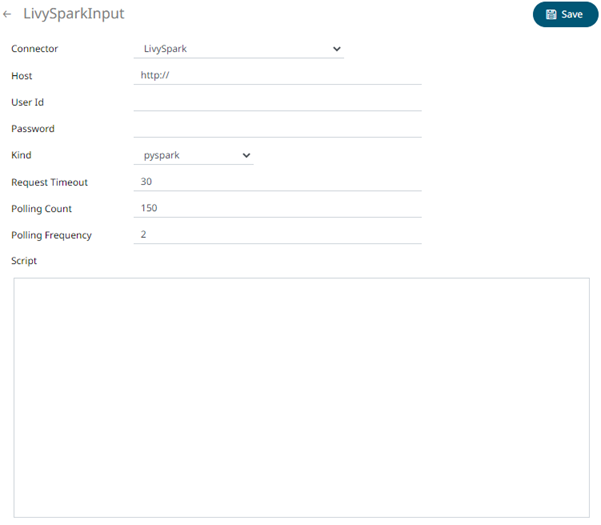
2. Enter or select the following properties:
|
Property |
Description |
|
Host |
Livy Spark host address. |
|
User Id |
User Id that will be used to connect to Livy Spark. |
|
Password |
Password that will be used to connect to Livy Spark. |
|
Kind |
Currently, the supported kind of connection to be used is pyspark (Interactive Python Spark session). |
|
Request Timeout |
Length of time to wait for the server response. Default is 30. |
|
Polling Count |
The number of polling done to the Livy Spark server to check if the status of the app is successful. Default limit is 150. |
|
Polling Frequency (in seconds) |
Frequency of the polling. Default is 2. |
|
Script |
The script to use. |
3. Click  . The new data source is added in the
Data Sources list.
. The new data source is added in the
Data Sources list.