

|
Panopticon Streams Applications
The main task of Panopticon Streams is to execute and manage streams applications. An application describes how data should be piped, transformed, and processed. Applications consist of a set of inputs, operators, and outputs and is described or constructed in an XML file.
It can be viewed as a directed graph with a set of nodes (or operators) and a set of edges (or streams) that are interconnected with each other.
|
Component |
Description |
|
ID |
The ID of the application config. It should be the same with the filename when loading an application config from the system. |
|
operators |
A list of operators (actions and functions). |
|
Streams |
A list of streams that describe the connection and the flow between operators. |
|
properties |
Application-specific defined properties. |
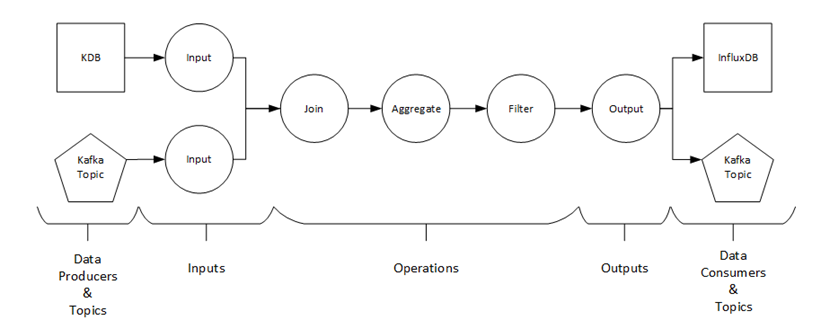
Figure 1-1. Panopticon Streams Framework
An application can either use Kafka topics or data producers, which generate data from a data source. The data producer also demonstrates to be the connection between the Panopticon Streams framework and the Panopticon core.
The Panopticon core has data connectors such as Kx kdb+, OneTick, and MS Excel that serve as data sources. Just like the application, the data source is also constructed or described in an XML file.
|
NOTE |
The current standalone Panopticon Streams application include the following data producers: ActiveMQ, AMPS, Elasticsearch 6.x, Elasticsearch 7.x, Google Cloud Pub/Sub, Influx DB, JDBC Database, JSON, Kafka, Kx kdb+, Kx kdb+ Tick, MongoDB, MQTT, MS Excel, OneTick, OneTick CEP, OneTick Cloud, Python, RabbitMQ, Rserve, Solace, Stream Simulator, Text, WebSocket, XML.
|
An application refers to a data source through its ID (or filename). There are several ways to create a data source of an application:
q Export data source with the PCLI tool
The PCLI tool extracts the already defined data sources in workbooks and saves them as CEP data sources.