NVIDIA V100 (Volta) versus NVIDIA A100 (Ampere)
Systems
- DGX-1
- 8x NVIDIA V100 (16 GB, max. 4 GPUs used)
- DGX-A100
- 8x NVIDIA A100 (40 GB, max. 4 GPUs used)
- nanoFluidX Software Stack
- nanoFluidX 2020.0 with single precision floating point arithmetics
Results
- Minimal Cube
- Simple cube of static fluid particles in rest
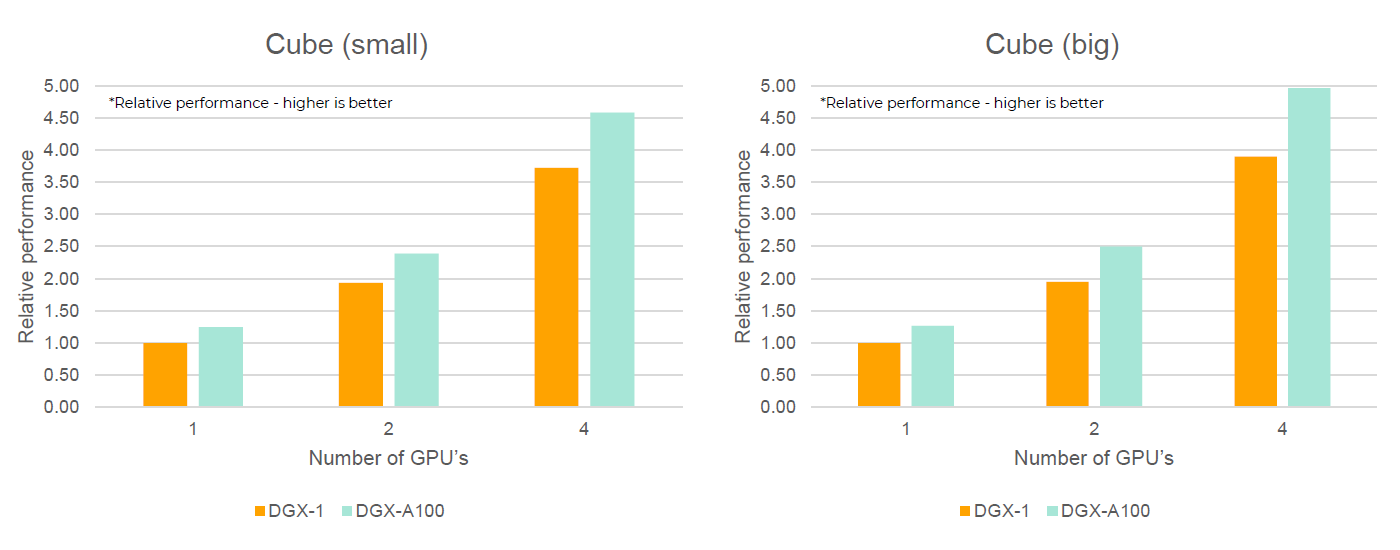
Figure 1.
- Dambreak
- Collapsing water column under gravity in domain (indicated by lines)
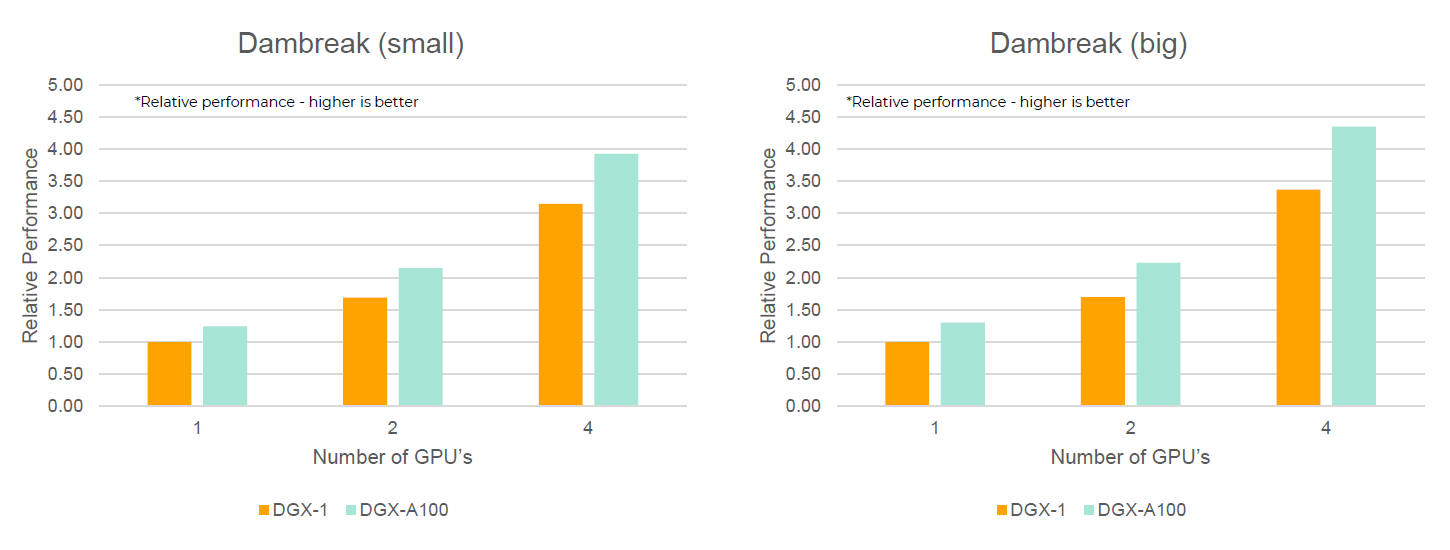
Figure 2.
- Altair E-Gearbox
- Showcase by Altair for E-Mobility application
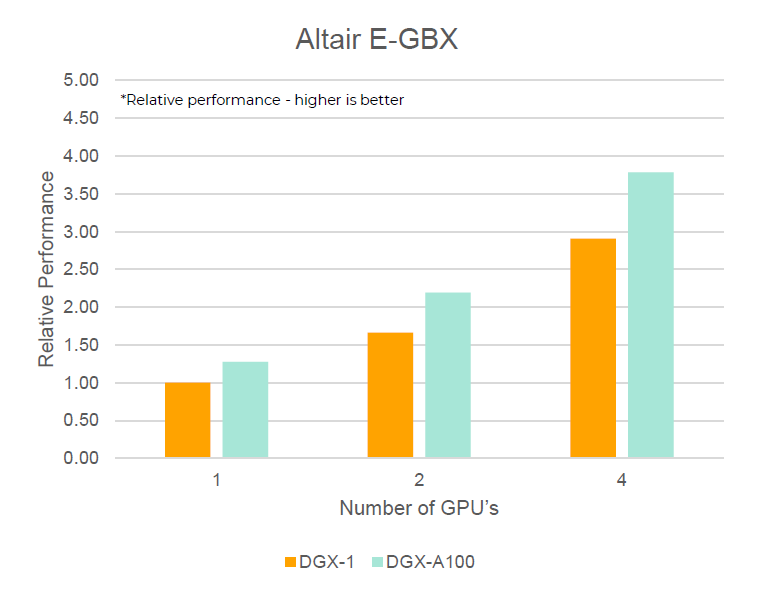
Figure 3.
- Aerospace Gearbox
- Another showcase for aerospace gearbox applications
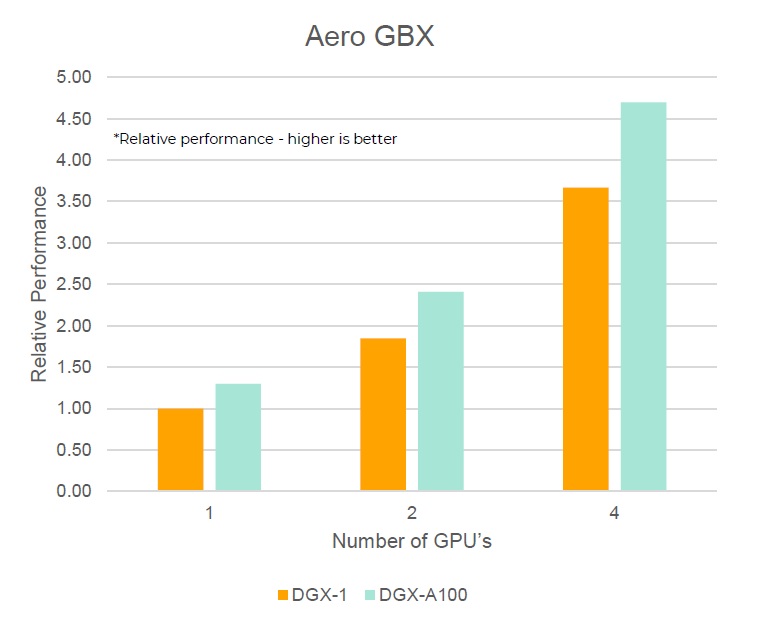
Figure 4.
Conclusions
Theoretical performance of core is approximately 25 percent faster on A100 (based on Minimal Cube, tendency to more for very large cases). Industrial cases seem to benefit slightly more (up to 30 percent). No noticeable difference regarding scalability.
Additional Notes
- Performance data in the graphs is always relative to one V100 on the DGX-1.
- All cases were run with the WEIGHTED particle interaction scheme.
- All solver output has been deactivated to focus on solver performance, but generally this does not change the results significantly.
- Slight performance uncertainty because of CUDA version as newer versions might apply more tailored optimizations. Compilation for V100 and A100 compute capabilities is not possible in CUDA 8.0. This improvement may be on the order of a few percent, generally not significant.
- Scalability between one and two GPU's is usually slightly impaired because some parts related to multi-GPU may be skipped entirely in single GPU runs.