NVIDIA V100 versus NVIDIA A40
Systems
- NVIDIA DGX 1
- 8x NVIDIA V100 (16 GB)
- Supermicro AS 4124GS TNR
- 8x NVIDIA A40 (40 GB)
- nanoFluidX Software Stack
- nanoFluidX 2022.0 with single precision floating point arithmetic
Results
- Minimal Cube
- Simple cube of static fluid particles in rest
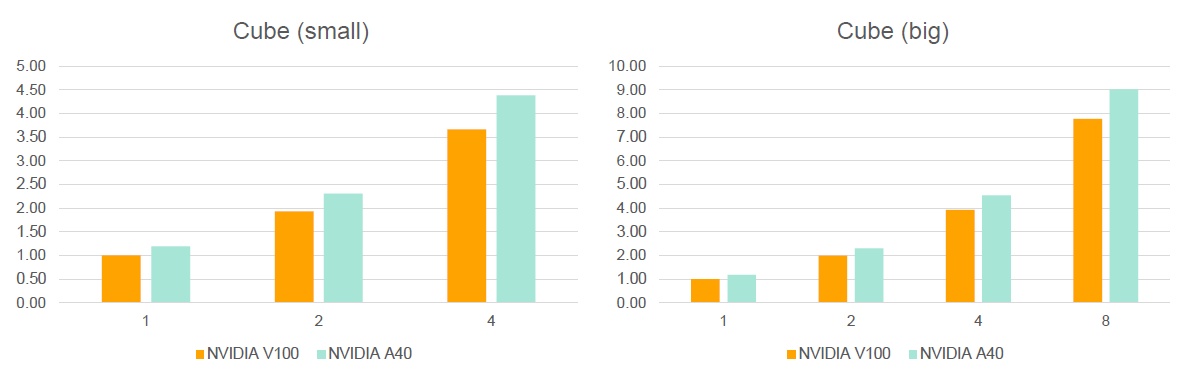
Figure 1.
- Dambreak
- Collapsing water column under gravity in domain (indicated by lines)
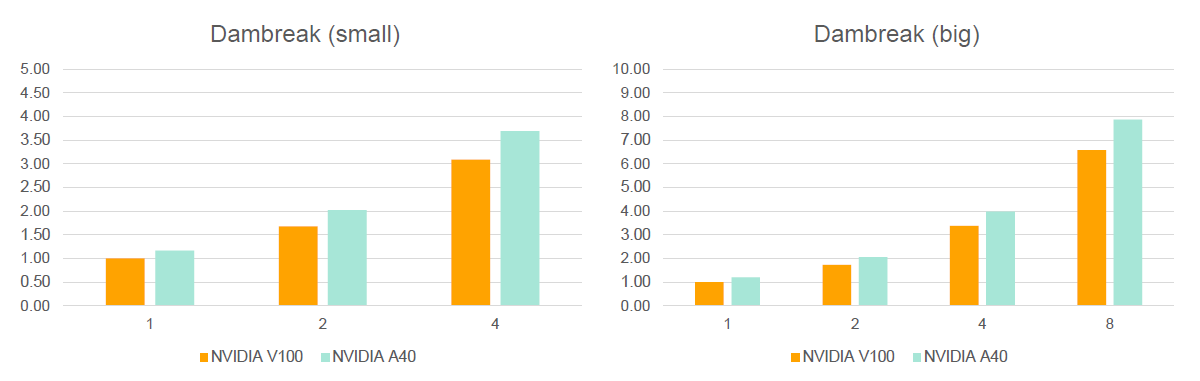
Figure 2.
- Altair E-Gearbox
- Showcase by Altair for E-Mobility application
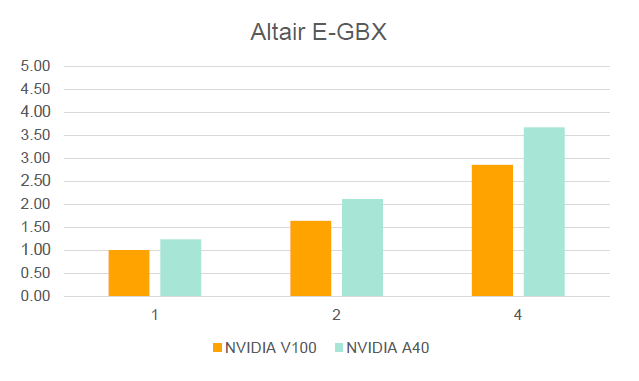
Figure 3.
- Aerospace Gearbox
- Another showcase for aerospace gearbox applications
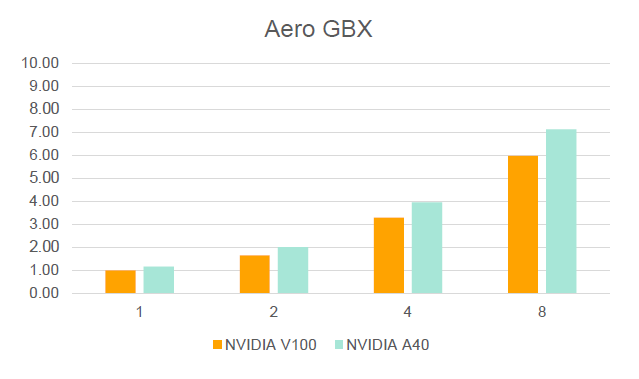
Figure 4.
Additional Notes
- Performance data in the graphs is always relative to one V100 on the DGX-1.
- All cases were run with the WEIGHTED particle interaction scheme.
- All case were run in single precision.
- All solver output has been deactivated to focus on solver performance, but generally this does not change the results significantly.
- Scalability between one and two GPU's is usually slightly impaired because some parts related to multi-GPU may be skipped entirely in single GPU runs.