Masking
Learn about Super Block masking, auto-masking, and properties.
Super Block Masking
A mask placed on a Super Block breaks the semi-global hierarchical scoping mechanism. A mask defines a set of parameters (mask parameters) and provides values for them, possibly as a function of parameters outside the Super Block. By analogy, an unmasked Super Block can be compared to an OML script and a masked Super Block, to an OML function.
Super Block Diagram
Consider the following diagram, inside a Super Block named SuperBlock:
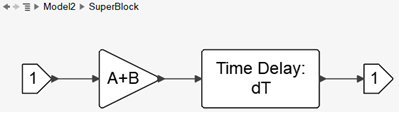
If the Super Block Context is empty, the parameters of this diagram are A, B and dT. If the Super Block is masked, then the mask should define these three parameters. Such a mask may look as follows:
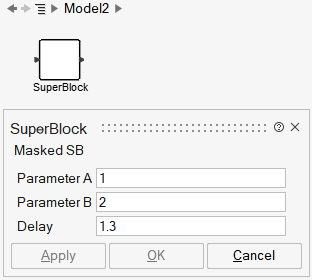
The mask parameter names are not directly visible on the mask GUI; they can be made visible by placing the cursor on top of the parameter description. In this case the mask parameters are named A, B and dT. The parameter values are defined by numerical values 1, 2 and 1.3. At this point the Super Block resembles a library block; the mask parameters are essentially local, private variables of the block, transparent to the user.
Auto-Masking
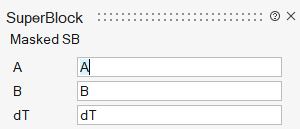
This mask defines parameters named A, B and dT inside the Super Block from model parameters with the same names outside the Super Block. This mask can then be edited, in particular for providing descriptions for the parameters (auto-masking places by default the name of the parameter in the description field).
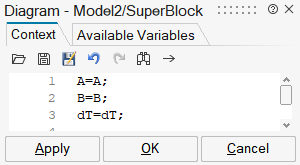
Creating New Blocks through Masking
Once a Super Block is masked, it can be used like a library block, and even placed in a block library. The values of the parameters should simply be replaced by default numerical values. Several Activate base library blocks are masked Super Blocks.
Creating a New Block with a Digital Chebyshev Filter
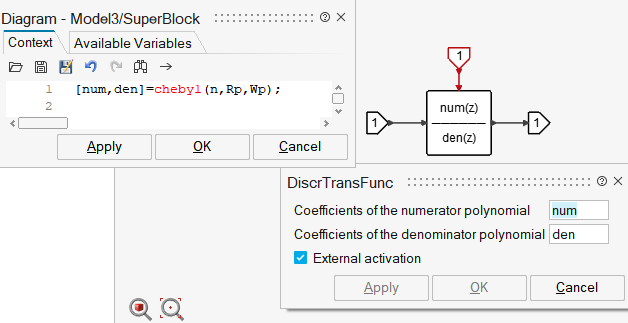
The new block can now be created by auto-masking this Super Block, and editing the mask to provide a description for the block, and, descriptions and default values for the parameters:
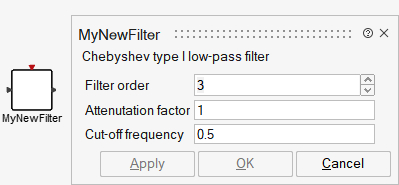
This block can now be used as such in the model or be placed in a library for wider usage.
Super Block Properties
There are several factors that can affect the way code is generated for the Super Block:
- Atomicity. If the Super Block is tagged Atomic, then the generated code is in general much simpler: if the Super Block has an input activation port, then it will be considered as the unique source of activation (in addition to always-activation if the Super Block includes always active blocks); and if it does not have an input activation port, then it inherits its activation as the union of the activations of its regular input signals. Not declaring a Super Block Atomic considers all possible combinations of the way the block can be activated, but in most code generation applications, the Atomic option is the appropriate choice. Note that tagging the Super Block Atomic changes its behavior also during simulation, so the choice can be validated by simulation before the actual code generation.
- Input and output port data types and sizes. The Super Block input and output block ports parameters can be used to set the data types and sizes of the corresponding signals. This information, which is only used for code generation, may have to be provided to allow the compiler to properly type the model signals. This additional information for code generation may be required because unlike the compilation of the full model for simulation, the compilation of the Super Block is done separately, without information about the environment. The typing constraints within the Super Block then may not impose enough constraints to uniquely determine the input/output signal types and sizes.
- Input time dependency. As for data types and sizes, the activation property of the signals entering the Super Block may need to be specified. In particular, if an input signal is always active, then the Time dependency parameter of the corresponding input port must be set.
The latter two points above concern information that user may need to provide to define the environment of the Super Block. So, it is important that it be consistent with the actual environment in the complete model used for simulation.