
|
Adding an Input Operator
Used to define the input data for the application model.
Steps:
1. In the Application page, click
![]() and
select Input
and
select Input  in
the Add Operator pane.
in
the Add Operator pane.
The
Input node  icon
displays in the Graph pane, as well as the properties to be
defined in the Operator Settings panel, and the preview of
the data in the Schema panel.
icon
displays in the Graph pane, as well as the properties to be
defined in the Operator Settings panel, and the preview of
the data in the Schema panel.
This operator serves as the initial source of the data in the application. The right (outbound) edge allows you to connect to other operators.
2. In the Operator Settings panel, define or select the following properties:
|
Property |
Description |
|
Node ID |
The ID of the input operator. |
|
Topic |
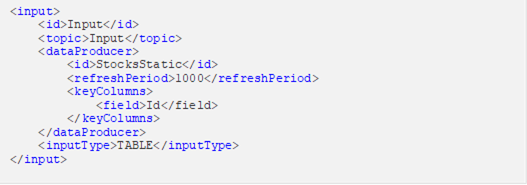
The stream of records or input you will be subscribed to. Check the Use Node ID box to use the value entered in the Input ID. Otherwise, uncheck the box and enter a new Topic ID. When adding Topic IDs, ensure they: · must be unique across an application · must be specified · must start with a letter (a to Z) or an underscore. Also, it can only contain letters (a to Z), numbers (0 to 9), and underscores |
|
Partition Count |
Enter the number of partitions for the Kafka topics that will be created for the Input operator. Partitions allow you to parallelize a topic by splitting the data in a particular topic across multiple brokers wherein, each partition can be placed on a separate machine to allow for multiple consumers to read from a topic in parallel. |
|
Input Type |
Select the input type: STREAM, TABLE, or GLOBAL_TABLE. STREAM will treat incoming data as a stream of records while TABLE creates a “materialized view” or snapshot table, representing the latest state of received key/value pairs. GLOBAL_TABLE can be seen as a materialized view that is distributed across all partitions. This is useful for keeping small, relatively static, data sets that needs to be joined with streaming data. |
|
Priority |
Select the priority of the node’s startup: · APPLICATION – running and successful completion of the node is critical in the application startup. · HIGHEST – highest priority but not critical. · HIGH (Default) – high priority but not critical. · STANDARD – standard priority. · LOW – low priority. |
|
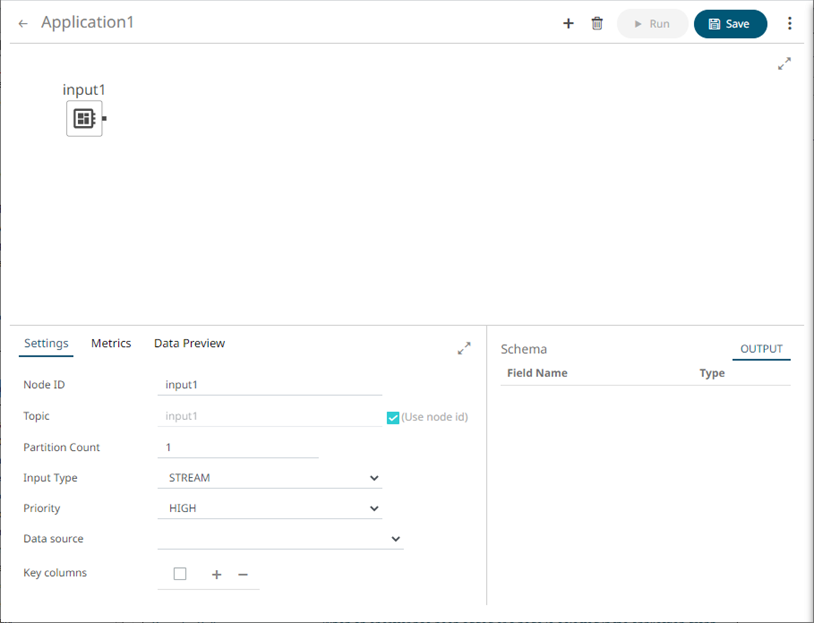
Data Source |
Select the data source. NOTES: · It is recommended to upload the data source first so they will be available for selection. · Selecting a non-streaming data source displays the Refresh Period (ms) property. Enter the refresh period for the data. This value determines when to periodically reload the data (from the beginning). · Setting the Refresh Period to any value less than or equal to zero will disable automatic data reload. The preview of the data (OUTPUT) is displayed in the Schema panel. |
|
Key Columns |
In Kafka, all messages are processed in a key/value fashion where the value represents the actual data payload or record. The key is used to determine how the key/value pairs are distributed across available partitions. If the key is null a round-robin approach is used to determine partition. For the TABLE and GLOBAL_TABLE input type, key is also essential for defining how records are segregated (keyed) in the table. Not providing a key will result in a single-row table. Post input, keying of records can be changed by using either the Rekey or Aggregation operators. |
|
NOTE |
Node ID, Topic, Input Type, and Data Source properties are required.
|
3. In the Key Columns section, click
![]() to add a
key column from the data source schema. Repeat to add more.
to add a
key column from the data source schema. Repeat to add more.
You
can also delete a key column in the list by checking its box and clicking
![]() .
.
4. Save the changes.
Example