表面状態 (仕上げと処理)
疲労破壊が表面から発生するとき、表面状態は疲労強度に影響を与える極端に重要な因子となります。表面仕上げと処理係数が疲労解析結果の補正として考慮されます。
表面仕上げ係数
C
f
i
n
i
s
h
が、表面の粗さを特性化するために用いられます。これは、研磨、機械加工、鍛造といった定性的な条件でカテゴリー分けされた仕上げの図に表されています。
1
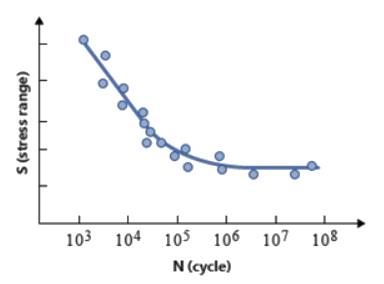
Figure 1. 鋼材の表面仕上げ補正係数
表面処理は部材の疲労強度を改善させることができます。NITRIDED(窒素化)、 SHOT-PEENED(ショットピーニング)、COLD-ROLLED(冷延)は表面処理補正として考慮されます。値を入力して表面処理係数
C
t
r
e
a
t
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWG0bGaamOCaiaadwgacaWGHbGaamiDaaqabaaaaa@3BA3@
を指定することもできます。
一般的な場合、全補正係数は
C
s
u
r
=
C
t
r
e
a
t
·
C
f
i
n
i
s
h
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaOGaeyypa0Jaam4qamaaBaaa
leaacaWG0bGaamOCaiaadwgacaWGHbGaamiDaaqabaGccaaMe8UaeS
4JPFMaaGzaVlaaysW7caWGdbWaaSbaaSqaaiaadAgacaWGPbGaamOB
aiaadMgacaWGZbGaamiAaaqabaaaaa@4E41@
処理タイプがNITRIDEDの場合、全補正整数は、
C
s
u
r
=
2.0
·
C
f
i
n
i
s
h
(
C
t
r
e
a
t
=
2.0
)
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaOGaeyypa0JaaGOmaiaac6ca
caaIWaGaaGjbVlabl+y6NjaaygW7caaMe8Uaam4qamaaBaaaleaaca
WGMbGaamyAaiaad6gacaWGPbGaam4CaiaadIgaaeqaaOWaaeWaaeaa
caWGdbWaaSbaaSqaaiaadshacaWGYbGaamyzaiaadggacaWG0baabe
aakiabg2da9iaaikdacaGGUaGaaGimaaGaayjkaiaawMcaaaaa@552A@
。
処理タイプがSHOT-PEENEDまたはCOLD-ROLLEDの場合、全補正整数は、
C
s
u
r
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaaaa@39D3@
= 1.0。これは表面仕上げの効果を無視する事を意味します。
疲労耐力限界FLは、
C
s
u
r
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaaaa@39D3@
により
F
L
'
=
F
L
*
C
s
u
r
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaamOraiaadY
eacaGGNaGaeyypa0JaamOraiaadYeacaGGQaGaam4qamaaBaaaleaa
caWGZbGaamyDaiaadkhaaeqaaaaa@3F6A@
.2セグメントのS-N曲線では、遷移点の応力も、
C
s
u
r
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaaaa@39D3@
を掛けることにより修正されます。
表面状態は、それらを各パートに割り当てるAssign Material ダイアログで定義できます 。
疲労強度減少係数
上で述べた係数に加えて、様々な他の因子が構造の疲労強度に影響を与える可能性があります。例えば、切欠き効果、寸法効果、荷重タイプ等です。疲労強度減少係数
K
f
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4samaaBa
aaleaacaWGMbaabeaaaaa@37DD@
はこのような補正を一体化して考慮するものとして導入されます。疲労耐力限界FLは、
K
f
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4samaaBa
aaleaacaWGMbaabeaaaaa@37DD@
により
F
L
'
=
F
L
/
K
f
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaamOraiaadY
eacaGGNaGaeyypa0JaamOraiaadYeacaGGVaGaam4samaaBaaaleaa
caWGMbaabeaaaaa@3D79@
疲労強度減少係数は、Assign Material ダイアログでパートまたはセットに割り当てられます 。
C
s
u
r
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaaaa@39D3@
と
K
f
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4samaaBa
aaleaacaWGMbaabeaaaaa@37DD@
の両方が指定された場合、疲労耐久限界FLは、
F
L
'
=
F
L
·
C
s
u
r
/
K
f
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaamOraiaadY
eacaGGNaGaeyypa0JaamOraiaadYeacaaMe8UaeS4JPFMaaGjbVlaa
doeadaWgaaWcbaGaam4CaiaadwhacaWGYbaabeaakiaac+cacaWGlb
WaaSbaaSqaaiaadAgaaeqaaaaa@46EA@
C
s
u
r
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaaaa@39D3@
と
K
f
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4samaaBa
aaleaacaWGMbaabeaaaaa@37DD@
は、その弾性部分がS-N定式化上にあることを通して、E-N定式化でも同様の影響を持ちます。E-N定式化の弾性部分では、公称疲労耐力限界FLがNcの弾性限界から内部的に計算されます。FLは、
C
s
u
r
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4qamaaBa
aaleaacaWGZbGaamyDaiaadkhaaeqaaaaa@39D3@
と
K
f
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4samaaBa
aaleaacaWGMbaabeaaaaa@37DD@
がある場合には修正されます。その弾性部分は送信された公称疲労限界とともに修正されます。
温度の影響
材料の疲労強度は温度の上昇と共に低下します。温度の影響は、疲労耐久限界FLを修正するために温度係数Ctemp を適用することで考慮できます。
Ctemp は、直接代入するか、もしくは、高温用FKMガイドラインに準拠したCtemp を計算するために、パート/要素セット全体の等温温度を定義することもできます。定義される温度は摂氏でなければなりません。
常温でのCtemp = 1
下記の材料について、FKMのガイドラインに従って定義された高温時のCtemp は、以下の表で強調表示されています。
ユーザー定義のCtemp は、0 < Ctemp <= 1の間の値を受け入れます
NONEに設定されたCtemp = 1
Type
温度条件
Ctemp 係数
None**これは下記以外の材料用
-
= 1
細粒構造用鋼
60℃ < T < 500℃
=1 - [10-3 x (T/℃)]
その他の鋼(ステンレス鋼を除く)
100℃ < T < 500℃
=1 - [1.4*10-3 x (T/℃-100)]
GS(鋳鋼および熱処理可能な鋳鋼)
100℃ < T < 500℃
=1 - [1.2*10-3 x (T/℃-100)]
GJS(ノジュラー鋳鉄)GJM(可鍛鋳鉄)
100℃ < T < 500℃
=1 - aT,D x (10-3 * T/℃)2
アルミニウム材料
50℃ < T < 200℃
=1 - [1.2*10-3 x (T/℃-50)]
材料グループ
GJS
GJM
GJL
aT,D
1.6
1.3
1.0
Ctemp とKf の両方が指定された場合、疲労耐久限界FLは、FL' = FL ⋅ Ctemp / Kf と修正されます。
疲労材料データにおけるばらつき
S-NおよびE-N曲線 (およびその他の疲労特性) は、完全反転の回転曲げ試験を通して、実験から得られます。通常実験結果には大きなばらつきを伴うため、データの統計的な特徴づけが必要になります(曲線の標準の誤差による曲線の修正には耐久確実性が用いられ、より高い信頼性レベルにはより大きな耐久確実性を必要とします)。
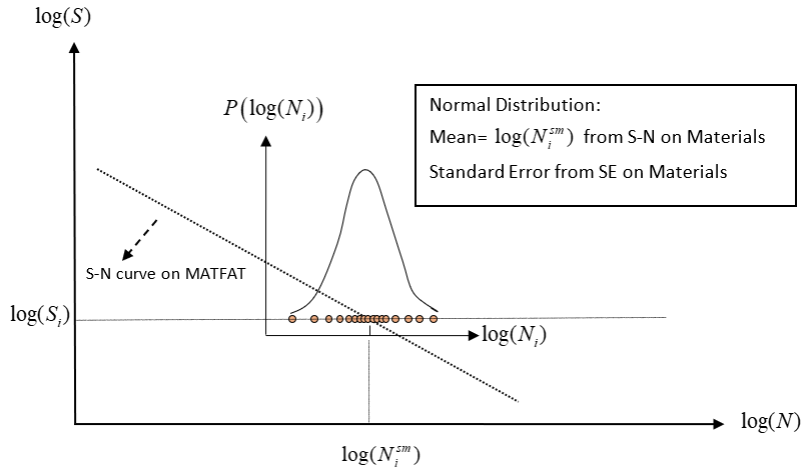
Figure 2. ばらつきデータのあるS-N曲線
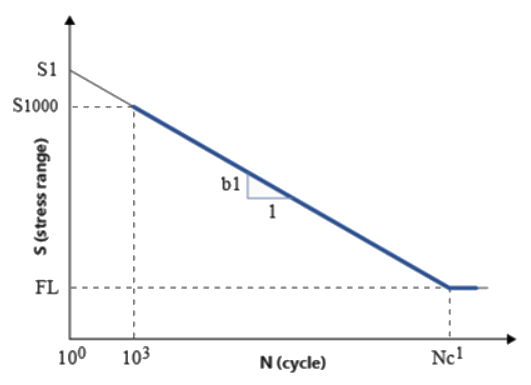
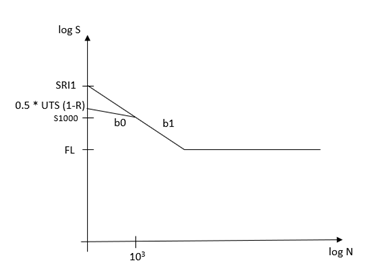
これらのパラメータを理解するために、1つの例としてS-N曲線を考えましょう。S-N実験データが、公称応力の大きさSaまたは範囲SRのどちらかに対する破壊のサイクル数Nが共に対数でプロットされると、そのSとNの関係は直線のセグメントで記述できます。通常、1つまたは2つのセグメントでの理想化が用いられます。
Figure 3. 両対数スケールでの1セグメントS-N曲線
S-Nのばらつきにより、同じ材料の同じサンプル試験体で、見込まれるS-N曲線に差が生じる状況について考えましょう。自然なばらつきにより、完全反転の回転曲げ試験の結果は、通常、応力範囲(S)と寿命(N)の両方のデータポイントでばらつきが生じます。対数スケールで見ると、Log (S)とLog (N)にばらつきがあります。具体的には、同じ応力範囲が与えられた場合の寿命のばらつきを見ると、データポイントは次のようになります。
S
2000.0
2000.0
2000.0
2000.0
2000.0
2000.0
Log (S)
3.3
3.3
3.3
3.3
3.3
3.3
Log (N)
3.9
3.7
3.75
3.79
3.87
3.9
多くのプロセスと同様に、Log (N)の分布は正規分布とみなされます。
log (S)の特定の値には、 log (N)の可能な値がすべて含まれています。この完全な母集団セットの平均は真の母集団の平均であり、未知です。したがって、サンプルのMaterial DB タブとMy Materialタブの MaterialsのSNカーブ
およびStandard Errorのユーザー入力サンプル平均 SN カーブに基づいて、log(N)の最悪の真の母集団平均値を統計的に推定します。 Material DBタブとMy Materialタブの 入力される SN 材料データは、データの生成に使用される特定のユーザーサンプルにおけるばらつきの通常分布の平均に基づいています。
Figure 4. S-NのばらつきのLog (N)分布の確率関数. 特定のユーザー定義サンプルデータ
応力範囲と寿命の両方のデータに実験的なばらつきが存在します。Assign Materialダイアログの 、log(N)のばらつきの標準誤差が入力(S-N曲線のSE フィールド)として必要です。サンプル平均は、 S-N曲線により
log
(
N
i
50
%
)
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaciiBaiaac+
gacaGGNbGaaiikaiaad6eadaqhaaWcbaGaamyAaaqaaiaaiwdacaaI
WaGaaiyjaaaakiaacMcaaaa@3E3A@
として与えられ、Assign Materialダイアログの SE フィールドを使用して入力されます。
指定されたS-N曲線が摂動なしに直接使用される場合、各データポイントでの正規分布の平均値が使用されるものとみなされ、デフォルトでは耐久確実性が50%となります。これは、
OptiStruct は、
Assign Material ダイアログの でユーザーが指定したサンプル平均を変更しないことを意味します。耐久確実性50%という値は、すべての用途で十分な値とは限らないため、
HyperLife では、ユーザーが定義した必要な耐久確実性となるように内部的にS-N材料データに摂動を与えることができます。このためには、次のデータが必要となります。
log (N)の正規分布の標準偏差(標準誤差)(Assign Materialの SE )
本解析に要するCertainty of Survival(Fatigue Moduleコンテキスト内のCertainty of Survival )。
正規分布またはガウス分布は確率密度関数であり、曲線の下の全面積は常に1.0になります。
ユーザー定義のSN曲線データは、正規分布であると想定されます。一般的には、次の確率密度関数表されます。
(1)
P (
x
s
) =
1
2 π
σ
s
2
e
−
(
x
s
−
μ
s
)
2
2
σ
s
2
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaamiuaiaacI
cacaWG4bWaaSbaaSqaaiaadohaaeqaaOGaaiykaiabg2da9maalaaa
baGaaGymaaqaamaakaaabaGaaGOmaiabec8aWjabeo8aZnaaBaaale
aacaWGZbaabeaakmaaCaaaleqabaGaaGOmaaaaaeqaaaaakiaadwga
daahaaWcbeqaaiabgkHiTmaalaaabaWaaeWaaeaacaWG4bWaaSbaaW
qaaiaadohaaeqaaSGaeyOeI0IaeqiVd02aaSbaaWqaaiaadohaaeqa
aaWccaGLOaGaayzkaaWaaWbaaWqabeaacaaIYaaaaaWcbaGaaGOmai
abeo8aZnaaDaaameaacaWGZbaabaGaaGOmaaaaaaaaaaaa@5180@
ここで、
x
s
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaamiEamaaBa
aaleaacaWGZbaabeaaaaa@3818@
データ値
log
(
N
i
)
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaciiBaiaac+
gacaGGNbGaaiikaiaad6eadaWgaaWcbaGaamyAaaqabaGccaGGPaaa
aa@3C17@
はユーザーサンプル。
μ
s
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaeqiVd02aaS
baaSqaaiaadohaaeqaaaaa@38D1@
サンプル平均
log
(
N
i
s
m
)
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbiqaaWmdciGGSb
Gaai4BaiaacEgacaGGOaGaamOtamaaDaaaleaacaWGPbaabaGaam4C
aiaad2gaaaGccaGGPaaaaa@3EDD@
。
σ
s
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaeq4Wdm3aaS
baaSqaaiaadohaaeqaaaaa@38DE@
不明なサンプルの標準偏差(Assign Materialダイアログの 標準誤差(SE)のみのユーザー入力)。
で。
上記の分布はユーザー定義サンプルの分布であり、完全な母集団空間ではありません。真の母集団平均は未知であるため、サンプル平均とサンプルSE から真の母集団の平均値の推定範囲を求め、その後ユーザーが指定した耐久確実性を使用して、サンプル平均を抽出します。
標準誤差は、全母集団から抽出されたサンプルのすべてのサンプル手段によって作成される正規分布の標準偏差です。1つのサンプル分布データから、標準誤差は通常、
S
E
=
(
σ
s
n
s
)
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4uaiaadw
eacqGH9aqpdaqadaqaceaacfWaaSWaaSqaaiabeo8aZnaaBaaameaa
caWGZbaabeaaaSqaamaakaaabaGaamOBamaaBaaameaacaWGZbaabe
aaaeqaaaaaaOGaayjkaiaawMcaaaaa@3FB0@
と推定されます、ここで
σ
s
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaeq4Wdm3aaS
baaSqaaiaadohaaeqaaaaa@38DE@
は、サンプルの標準偏差で、
n
s
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaamOBamaaBa
aaleaacaWGZbaabeaaaaa@380E@
はサンプルのデータ数です。すべてのサンプル平均におけるこの分布の平均は、実際には真の母集団の平均と同じです。ユーザーにより与えられる耐久確実性は、すべてのサンプル平均のこの分布に適用されます。
一般的には、正規分布関数を標準正規分布曲線(平均=0.0、標準誤差=1.0の正規分布)に変換します。これにより、Zテーブルを介して耐久確実性を直接利用することができます。
Note: 耐久確実性は、確率密度関数の必要なサンプルポイント間の曲線の下の面積に等しくなります。正規分布曲線の下の面積を直接(標準正規分布曲線に変換せずに)計算することは可能ですが、参照用の標準正規分布表に比べて計算の負荷が大きくなります。したがって、一般的に使用されている方法では、まず現在の正規分布を標準正規分布に変換してから、標準正規分布表を使用して入力した耐久確実性をパラメータ化します。
すべてのサンプル平均の通常の分布では、この分布の平均
μ
は実際の母集団の平均と同じであり、その範囲が推定対象となります。
統計的に、真の母集団の平均の範囲を次のように推定できます。
(2)
log (
N
i
s m
) − z * S E ≤ μ ≤ log (
N
i
s m
) + z * S E
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaciiBaiaac+
gacaGGNbGaaiikaiaad6eadaqhaaWcbaGaamyAaaqaaiaadohacaWG
TbaaaOGaaiykaiabgkHiTiaadQhacaGGQaGaam4uaiaadweacqGHKj
YOcqaH8oqBcqGHKjYOciGGSbGaai4BaiaacEgacaGGOaGaamOtamaa
DaaaleaacaWGPbaabaGaam4Caiaad2gaaaGccaGGPaGaey4kaSIaam
OEaiaacQcacaWGtbGaamyraaaa@539A@
つまり、
(3)
log (
N
i
s m
) − z * S E ≤ log (
N
i
m
) ≤ log (
N
i
s m
) + z * S E
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaciiBaiaac+
gacaGGNbGaaiikaiaad6eadaqhaaWcbaGaamyAaaqaaiaadohacaWG
TbaaaOGaaiykaiabgkHiTiaadQhacaGGQaGaam4uaiaadweacqGHKj
YOciGGSbGaai4BaiaacEgacaGGOaGaamOtamaaDaaaleaacaWGPbaa
baGaamyBaaaakiaacMcacqGHKjYOciGGSbGaai4BaiaacEgacaGGOa
GaamOtamaaDaaaleaacaWGPbaabaGaam4Caiaad2gaaaGccaGGPaGa
ey4kaSIaamOEaiaacQcacaWGtbGaamyraaaa@58F7@
左側の値はより保守性が高いので、次の式を使用してSN曲線を変化させます。
(4)
log (
N
i
m
) = log (
N
i
s m
) − z * S E
MathType@MTEF@5@5@+=
feaagKart1ev2aaatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaciiBaiaac+
gacaGGNbGaaiikaiaad6eadaqhaaWcbaGaamyAaaqaaiaad2gaaaGc
caGGPaGaeyypa0JaciiBaiaac+gacaGGNbGaaiikaiaad6eadaqhaa
WcbaGaamyAaaqaaiaadohacaWGTbaaaOGaaiykaiabgkHiTiaadQha
caGGQaGaam4uaiaadweaaaa@4A56@
ここで、
log (
N
i
m
)
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaciiBaiaac+
gacaGGNbGaaiikaiaad6eadaqhaaWcbaGaamyAaaqaaiaad2gaaaGc
caGGPaaaaa@3D0A@
摂動値
log (
N
i
s m
)
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaciiBaiaac+
gacaGGNbGaaiikaiaad6eadaqhaaWcbaGaamyAaaqaaiaadohacaWG
TbaaaOGaaiykaaaa@3E02@
ユーザー指定のサンプル平均(Materials のSN曲線)
S E
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaam4uaiaadw
eaaaa@3799@
標準誤差(Materials のSN)
z
MathType@MTEF@5@5@+=
feaagKart1ev2aqatCvAUfeBSjuyZL2yd9gzLbvyNv2CaerbuLwBLn
hiov2DGi1BTfMBaeXatLxBI9gBaerbd9wDYLwzYbItLDharqqtubsr
4rNCHbGeaGqiVu0Je9sqqrpepC0xbbL8F4rqqrFfpeea0xe9Lq=Jc9
vqaqpepm0xbba9pwe9Q8fs0=yqaqpepae9pg0FirpepeKkFr0xfr=x
fr=xb9adbaqaaeGaciGaaiaabeqaamaabaabaaGcbaGaamOEaaaa@36F6@
の値は耐久確実性の入力値に基づいて標準正規分布Zテーブルから求められる。以下に、該当する耐久確実性の典型的なZの値をいくつか示します。
Z値(計算値) 耐久確実性(入力値) 0.0
50.0
0.5
69.0
1.0
84.0
1.5
93.0
2.0
97.7
3.0
99.9
上記の例(S-N)に基づいて、S-N曲線が必要な耐久確実性と標準誤差の入力に変更される様子がわかります。このテクニックにより、統計的手法を使用して疲労材料データのばらつきを処理し、必要な耐久確率値のデータを予測することができます。
複数のSN曲線の調整
以下の調整が、複数平均応力SN曲線、複数応力比SN曲線、およびHaigh図に適用されます。
耐久確実性
材料の疲労強度の不確実性は、log(stress)の標準誤差と耐久確実性を使用して考慮することができます。
例えば、log(stress)の標準誤差が0.2で、耐久確実性を99.7%にしなければならない場合は、HyperLife が次のように複数SN曲線を調整します。
log(fatigue strength) = log(user defined fatigue strength) – 3 x 0.2
疲労強度 = (ユーザー定義の疲労強度) x 10(-3 x 0.2)
この例では、ユーザー定義の疲労強度が、正規化されたガウス分布の99.7%に相当する3標準誤差だけ減算されます。
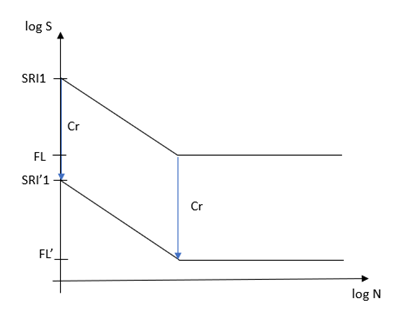
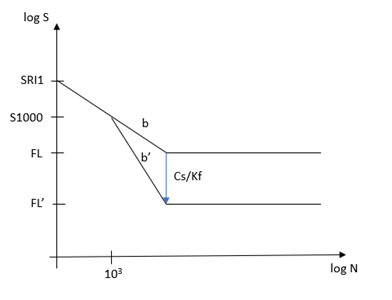
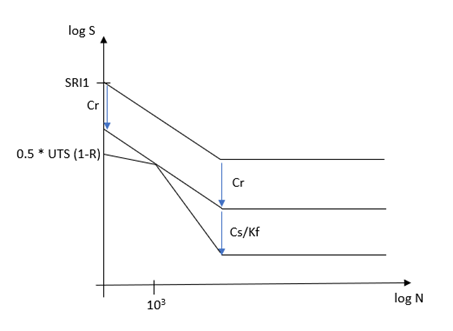
表面状態と疲労強度減少係数
表面状態の係数(Cs)と疲労強度減少係数(Kf)が、次のように疲労強度に適用されます。
疲労強度 = (ユーザー定義の疲労強度) x K’
ここで、 K’ = 1.0 for N <= 1000
K’ = Cs/Kf for N > Nc1
log(K’) = log(Cs/Kf) x (3-logN) / (3-logNc1) for 1000 < N < Nc1
Nc1: 遷移ポイント