ワークフロー
ここではHyperStudyのワークフローについて学習します。取り上げる対象はスタディを設定するための各フェーズです。
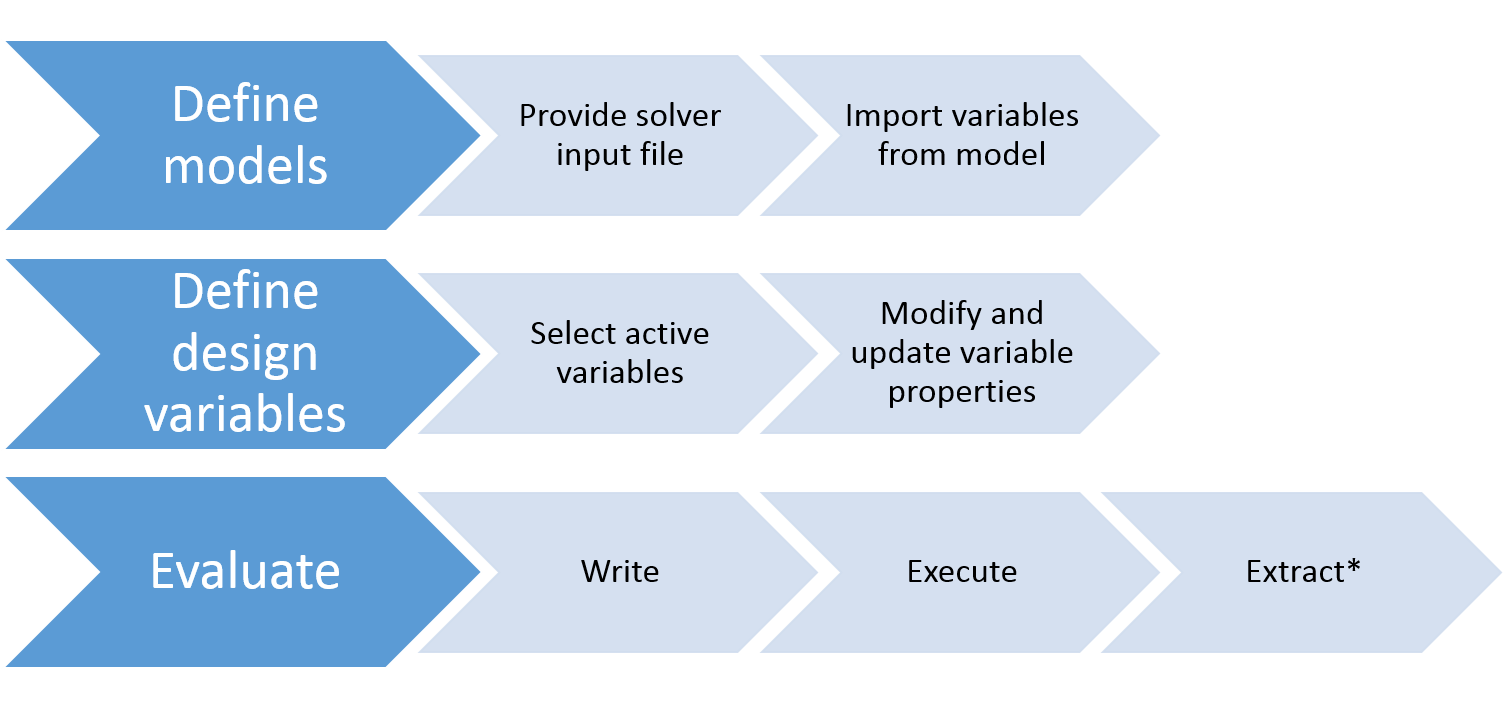
HyperStudyの一般的なワークフローを以下に示します。
-
4種類のアプローチである“実験計画法”、“フィット”、“確率論的”、または“最適化”のいずれかを使用してスタディを実行します。
FekoはHyperStudyの登録済みソルバーです。ソルバーを登録すると、ワークフローの大半がHyperStudyに統合されます。設定プロセスは以下の各フェーズで構成されています。
- モデルの定義
-
このフェーズではソルバーの入力ファイルを用意します。HyperStudyでは、設計変数の現在の値を使用して、実行ごとに初期テンプレートファイルからこの入力ファイルが作成されます。モデルを追加済みであれば、Import Variablesボタンをクリックすることでそのモデルが解析され、変更できる設計変数が特定されます。これらの変数を以降のアプローチで使用してモデルのさまざまな置換を生成できます。
- 設計変数の定義
-
モデル定義のフェーズで変数のテーブルがインポートされています。ここでは、これら変数の編集、非アクティブ化、値の範囲の設定が可能です。
- 評価
-
このフェーズでは、ファイルの書き込み、ソルバーの実行、その結果からの値の抽出を実行します。
-
書き込み:書き込みフェーズでは、モデルのコピーを格納するサブディレクトリと、モデルがその実行の際に依存するすべてのファイルを格納するサブディレクトリがHyperStudyによって作成されます。モデル変数が更新された後でソルバーが実行されます。
-
実行:実行フェーズでは、ソルバーを実行して出力データを生成します。未加工のシミュレーションデータに対する後処理(出力データに対するスクリプトの実行など)があれば、このフェーズですべて実行されます。
-
抽出:抽出フェーズでは、出力の応答値を特定し、それを抽出してHyperStudyに戻します。
-
Note: 抽出フェーズではASCIIファイルを処理できます。Figure 1. HyperStudyとFekoの統合ワークフロー