Flux e-Machine Toolbox:入力パラメータ
概要
Fluxで連成コンポーネントを開いた後、テストを実行する前にいくつかの入力パラメータを定義する必要があります。これらのパラメータを使用すれば、以下の操作が可能です:
- Fluxプロジェクトの解析をパイロット実行する
- 解析オプション(演算の分散やメモリ)を指定する
- さまざまなパフォーマンスマップを計算して構築する
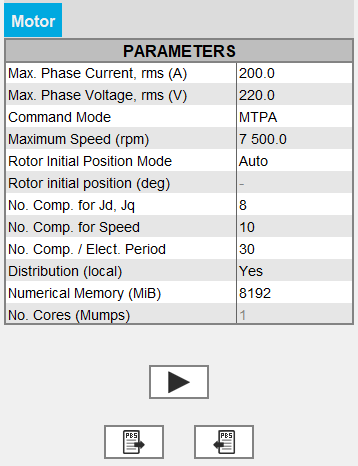
入力パラメータ:目的のデータ
- 最大相電流RMS
- 最大相電圧RMS
- コマンドモード:
- MPTA:標準解析ワークフローでの電流あたりの最大トルク
- MTPV:標準解析ワークフローでの電圧あたりの最大トルク
- MTPA Fast:高速解析ワークフローでの電流あたりの最大トルク
- MTPV Fast:高速解析ワークフローでの電圧あたりの最大トルク
- 電気機械の最大許容回転速度
入力パラメータ:回転子の初期角度
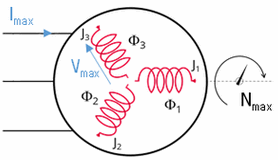
回転子の初期角度は、パーク変換を適用するために必要な変数です。次の2つのいずれかを選択できます:
- User: 回転子の初期角度がわかっている場合は、その値を入力します
- Auto: 回転子の初期角度の値が自動的に計算されますこのパラメータの目的は、基準相(相Aなど)によって空隙に発生する磁束密度と回転子の位置を合わせるために、t=0sの回転子角度を求めることにあります。回転子の初期角度を計算するために、2つのシミュレーションが実行されます。空隙での磁束密度を計算するために、その空隙中央の経路が自動的に定義されます。
入力パラメータ:必要とする計算回数
- 標準解析ワークフロー(コマンドモードMTPAおよびMTPV)の場合:
- JdとJqの計算回数(デフォルトは8回)
- 回転速度の計算回数(デフォルトは10回)
- 電気的周期ごとの計算回数(デフォルトは30回)
注: 計算の総数は4の積になるため、デフォルト値を使用した場合は、19,200個の計算ポイントが存在することになります。トルク-速度の良好なエンベロープを得るには、十分な量のポイントを設定する必要があります。したがって、計算時間がきわめて長くなることがあります。結果の精度と解析に要する時間との関係が適切になるように、各値を選択する必要があります。デフォルト値を使用することで、この適切な関係が得られます。 - 高速解析ワークフロー(コマンドモードMTPA
FastおよびMTPV Fast)の場合:
- JdとJqの計算回数(デフォルトは8回)
注: これら2つのコマンドモードMTPA FastおよびMTPV Fastの場合、- パラメトリック解析プロセスはパラメータJdとJqに対してのみ実行されます。
- Number of computations for the speedとNumber of computations per electrical periodはどちらも変更できません。これら2つの欄は無効(灰色表示)になっています。
この高速解析ワークフロー(MTPA FastおよびMTPV Fastコマンドモード)を使用すると、標準解析ワークフロー(MTPAおよびMTPVコマンドモード)よりも計算速度が速くなります。
入力パラメータ:演算の分散とメモリのオプション
- Activate or not the local distribution(2022.1バージョン以降のWindowsおよびLinux上)
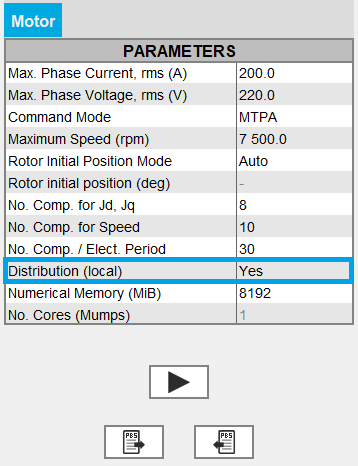
重要: 分散が構成済みであることを確認します。このオプションをYesにしないと、解析の演算が分散されず、逐次演算になります。分散構成の詳細については、以下をご参照ください。 Fluxによるパラメトリック分散
注: Skewにはコンピューティングの分散機能が実装されていません。 - Fluxプロジェクトの解析プロセスに割り当てる演算メモリ量を指定します。
FeMT 2021以降、テストを実行するための新しいメモリモードとして、Dynamicメモリモードが追加されています。
したがって、現在のメモリモードはUser(静的)とDynamicの2種類です。
- User(静的)メモリモードを使用している場合は、Fluxプロジェクトの解析プロセスに割り当てられた計算メモリ値(MiB単位)が表示されます。この値はユーザー側で変更できます。
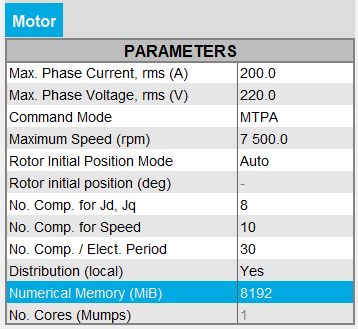
一方、ユーザーは0を入力することで、Dynamic数値メモリモードに切り替えることができます。
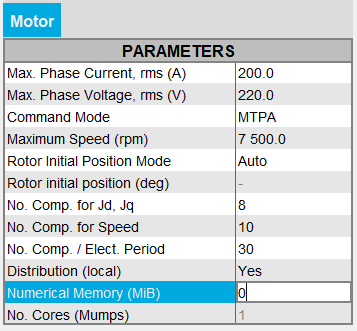
 注: 2022.1よりも前のバージョンのFeMTの場合、ユーザーがFeMTでDynamicメモリモードに切り替えることはできませんでした。Dynamicメモリモードでテストを実行するには、Dynamicメモリモードで実行しているFluxで連成コンポーネントを再生成する必要がありました。
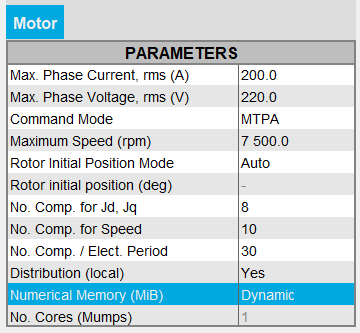
注: 2022.1よりも前のバージョンのFeMTの場合、ユーザーがFeMTでDynamicメモリモードに切り替えることはできませんでした。Dynamicメモリモードでテストを実行するには、Dynamicメモリモードで実行しているFluxで連成コンポーネントを再生成する必要がありました。 - Dynamicメモリモードを使用している場合は、Dynamicが表示され、使用される演算メモリ量はFluxによって動的に管理されます。したがって、このモードでは、ユーザーが演算メモリの値を設定することはありません。
一方、ユーザーはMiBで数値を入力することで、User数値メモリモードに切り替えることができます。
警告: Dynamic数値メモリモードからUser数値メモリモードに切り替える際に、ユーザーはプロジェクトの解析に必要な数値メモリを把握して、十分に高い値を設定する必要があります。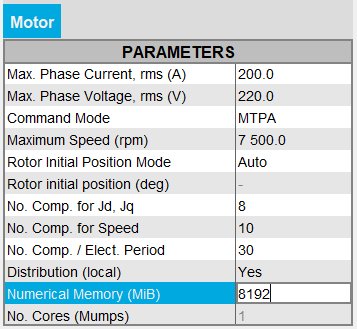
注: 2022.1よりも前のバージョンのFeMTの場合、ユーザーがFeMTでUserメモリモードに切り替えることはできませんでした。Userメモリモードでテストを実行するには、Userメモリモードで実行しているFluxで連成コンポーネントを再生成する必要がありました。
- User(静的)メモリモードを使用している場合は、Fluxプロジェクトの解析プロセスに割り当てられた計算メモリ値(MiB単位)が表示されます。この値はユーザー側で変更できます。
- Mumpsソルバーで初期プロジェクトに使用されるコア数
- ローカル分散がYesの場合、Mumpsソルバーで使用されるコア数の値は1に固定され、ユーザーからはアクセスできなくなります(この場合は、このパラメータが灰色表示になり、表示されている値は考慮されていません)。
- ローカル分散がNoの場合は、コア数として入力された値がMumpsソルバーで考慮されます。デフォルトでは、この値は4です。
- ローカル分散がYesでも、分散が適切に設定されていないと、Mumpsソルバーでは入力したコア数が考慮されます。