ハイブリッド共有 / 分散メモリ並列化(SPMD)
Single Program, Multiple Data(SPMD)は計算における並列テクニックで、プログラムを複数のサブセットに分割し、それらを複数プロセッサ / マシン上で同時に実行することによって、より速く結果を得るために使用されます。
| アプリケーション | バージョン | サポートされるプラットフォーム | MPI |
|---|---|---|---|
| OptiStruct SPMD | 2022 | Linux 64 bit | IBM Platform MPI 9.1.2(以前のHP-MPI) または Intel MPI - Version 2018 Update 4(推奨) |
| Windows 64 bit | IBM Platform MPI 9.1.2(以前のHP-MPI) または Intel MPI - 5.1.0.078(推奨) |
- 領域分割法 (DDM)
- マルチモデル最適化 (MMO)
- フェイルセーフトポロジー最適化 (FSO)
領域分割法
領域分割法(DDM: Domain Decomposition Method)は、解析と最適化に使用できます。DDMはOptiStructにおける並列化オプションで、特にコア数の大きい(9以上)マシンで従来の共有メモリ並列化アプローチと比べるとスケーラビリティを向上し、モデルの解析時間を大幅に短縮することができます。
DDMでは、モデルの属性に応じて2つのメインレベルの並列化が可能です。
DDM Level 1 – タスクベースの並列化
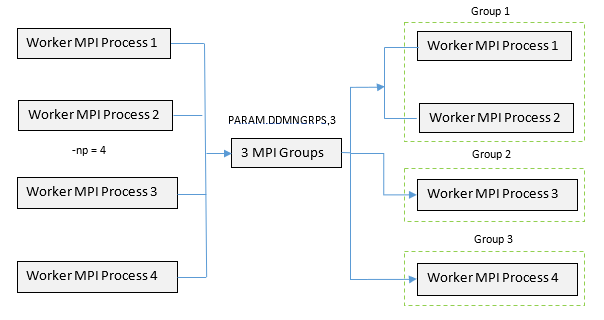
図 1. 3つのグループに分割される4つのMPIプロセスを有する(
-np=4)のDDMセットアップの例. これは、DDM Level 1で複数の並列化可能なタスクを含んだモデルの並列化をどのようにグループ分けできるかの例です。| サポートされている解析 | DDMでのタスクベースの並列化可能エンティティ | 非並列化可能タスク |
|---|---|---|
| 線形静解析 | √ 2つまたはそれ以上の静的境界条件が並列化されます(マトリックスの三角化は計算処理を重くするため、並列化されるステップです)。 √ 感度は最適化用に並列化されます。 |
√ 反復解法は並列化されません(直接解法のみ並列化されます)。 |
| 非線形静解析 | √ 2つまたはそれ以上の非線形静的サブケースは並列化されます。 | 右記の注を参照; 1 √ 最適化は並列化されません。 |
| 座屈解析 | √ 2つまたはそれ以上の座屈サブケースは並列化されます。 √ 感度は最適化用に並列化されます。 |
|
| 直接法による周波数応答解析 | √ 荷重周波数は並列化されます。 | √ 最適化は並列化されません。 |
| モーダル法による周波数応答解析 | √ 異なるモード空間は並列化されます。 | √ 最適化は並列化されません。 |
| 複数の開始ポイントを擁するDGLOBALグローバルサーチ最適化 | √ 開始ポイントは並列化されます。 | |
| マルチモデル最適化 | √ メインファイルにリストされているモデルは、指定された全体の-npの数および / またはメインファイル内の各ファイルについて定義されている-npの数に応じて並列化されます。 |
√ タスクベースの並列化は、各MMOモデル内では適用されません。MMOでの個々のモデルについては、幾何分割(DDM level 2)のみが実行されます。 |
- 線形静解析の場合、Level 1 DDM(タスクベースの分割)は:
- 微小変位および大変位非線形静解析の両方についてサポートされています。
- デフォルトではオフとなっており、PARAM,DDMNGRPSの使用、または
-ddmngrps実行オプションによってアクティブにすることができます。その他上記のサポートされている解析では、マルチレベルDDMはデフォルトでアクティブとなっています。 - 単一の非線形プリテンショニングサブケースが存在する場合、他のすべての非線形サブケースは同じプリテンショニングチェーンの一部でなければなりません; そうでない場合、実行は通常のDDMに切り替わります。
- 非線形過渡解析は現時点ではサポートされていません。
- 非線形静解析でのマルチレベルDDMの設定例: 以下の例のすべてのサブケースは、非線形静的サブケース(NLSTAT)対応のセットアップ - Example 1:
SUBCASE 1 PRETENSION=5 SUBCASE 2 PRETENSION=6 STATSUB(PRETENS)=1 CNTNLSUB=1 SUBCASE 3 STATSUB(PRETENS)=2 CNTNLSUB=2 SUBCASE 4 STATSUB(PRETENS)=2 CNTNLSUB=2PARAM, DDMNGRPS, 2が指定された場合、サブケース1と2は最初に通常のDDM幾何分割のみで実行され、その後サブケース3と4はマルチレベルタスクベースのDDMと並列で実行されます。
対応のセットアップ - Example 2:SUBCASE 1 PRETENSION=5 SUBCASE 2 STATSUB(PRETENS)=1 CNTNLSUB=1 SUBCASE 3 STATSUB(PRETENS)=1 CNTNLSUB=1PARAM, DDMNGRPS, 2が指定された場合、サブケース1は最初に通常のDDM幾何分割のみで実行され、その後サブケース2と3はマルチレベルタスクベースのDDMと並列で実行されます。
対応のセットアップ - Example 3:SUBCASE 1 NLPARM = 1 SUBCASE 2 NLPARM = 1PARAM, DDMNGRPS, 2が指定された場合、サブケース1と2はマルチレベルタスクベースのDDMと並列で実行されます。
非対応のセットアップ - Example 4:SUBCASE 1 PRETENSION=5 SUBCASE 2 PRETENSION=6 STATSUB(PRETENS)=1 CNTNLSUB=1 SUBCASE 3 STATSUB(PRETENS)=2 CNTNLSUB=2これは、マルチレベルDDMではサポートされません。PARAM, DDMNGRPS, 2が指定されていても、OptiStructは通常のDDMに切り替えます。
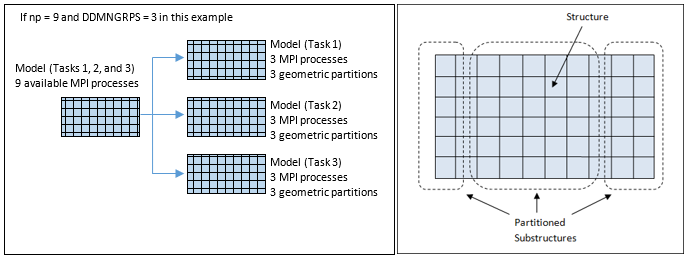
図 2. (a): DDM Level 1: タスクの並列化; (b) DDM Level 2: 各タスクベースモデルの幾何分割. MPIプロセスの数とMPIグループの数に応じて
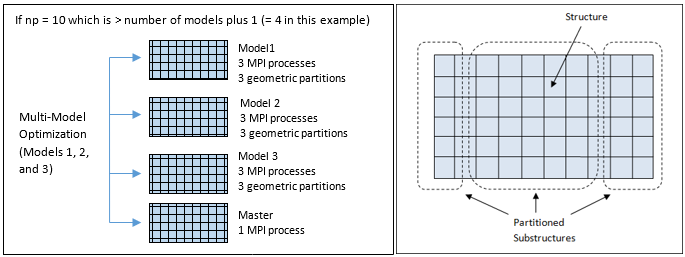
図 3. (a): DDM Level 1:MMOモデルの並列化; (b) DDM Level 2: MMO最適化モデルの一部または全ての幾何分割. MPIプロセスの数とMPIグループの数に応じて
DDM Level 2 – 幾何分割の並列化
並列化のレベル2は、分割されたタスクのレベルで起こります。分割された各タスクは、モデルの幾何分割によって更に並列化することが可能です。これらの幾何分割は、MPIグループの数と、各グループ内のMPIプロセスの数に応じて生成され、割り当てられます。
レベル2のDDMプロセスは、グラフ領域分割アルゴリズムを使って自動的に幾何構造を複数の(対応するグループ内のMPIプロセスの数に等しい)領域に分けます。FEA解析 / 最適化の実行時、個々の領域 / MPIはその領域に関連する計算のみを処理します。こうした手順には、要素マトリックスアセンブリ、線形解析、応力計算、感度計算などが含まれます。
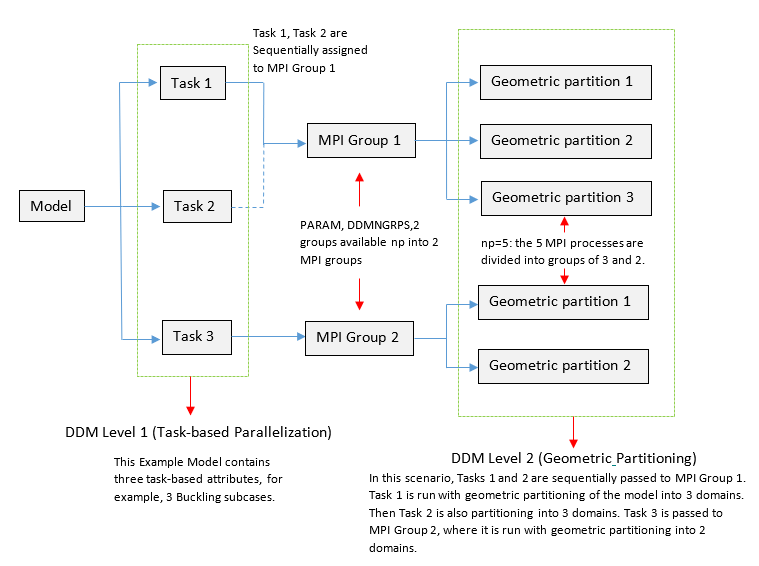
図 4. 5つのMPIプロセスを有する(
-np=5)DDMセットアップの例. モデルは3つのタスク属性(たとえば、3つの座屈サブケース、または3つのDFREQ荷重周波数、など)を有しています。PARAM, DDMNGRPS,2が定義されています。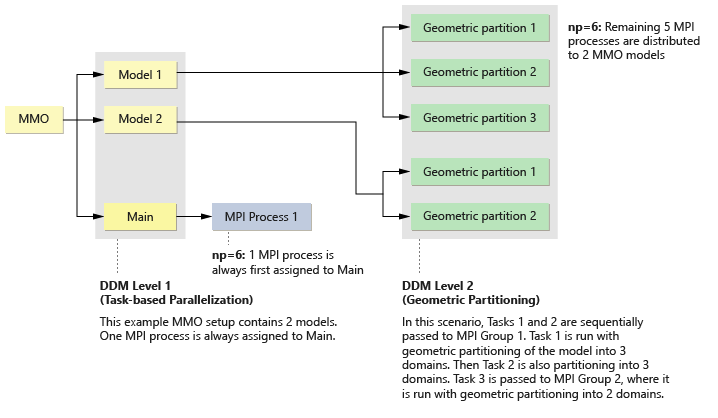
図 5. 6つのMPIプロセスを有する(
-np=6)DDMセットアップの例. MMOセットアップは2つのモデルを有します。PARAM,DDMNGRPSはMMOと併せて使用してはいけません。レベル2並列化のためのDDM機能は、このタスクに割り当てられているMPIグループ内で使用可能なMPIプロセスの数に基づいたモデルの直接幾何分割です。
DDM Level 2は純粋に幾何分割であり、PARAM,DDMNGRPS,MINを設定することでLevel 2 DDMのみを実施させることができます。これは、指定のモデルに割り当てることのできるグループの数を最小化し、それによって純粋な幾何分割並列化に導きます。
Level 1並列化とLevel 2並列化の両方を使ったハイブリッドDDM並列化は、PARAM,DDMNGRPS,AUTO or PARAM,DDMNGRPS,#を設定することで可能となります。ここで、#はMPIグループの数です。あらゆるDDMランでデフォルトであるAUTOの場合、OptiStructは、モデルの属性と指定されている-npに応じて、特定のモデルについてのMPIグループの数を試行錯誤的に割り当てます。
-npとMPIグループの数に応じて実行されます。PARAM,DDMNGRPS,<ngrps>はオプションのパラメータで、どのDDMランについてもAUTOが常にデフォルトです。モデルはまず並列化可能なタスク / 開始ポイントに分割されます(Level 1をサポートしている解析タイプについては、表 2をご参照ください)。続いて、各タスク / 開始ポイントはMPIグループにより順番に解析されます。各MPIグループは、1つまたは複数のMPIプロセスで構成されます。1つのMPIグループが複数のMPIプロセスから成る場合、タスク / 開始ポイントはそのMPIグループ内で幾何分割によって解析されます(1つのグループ内のMPIプロセスの数は、幾何分割の数と同等です。幾何分割Level 2 DDMをサポートしている解析については、DDM Level 2並列化(幾何分割)についてサポートされる解析タイプをご参照ください)。- グローバルサーチオプションの場合、MPIプロセスグループは、DGLOBALエントリのグループの数(NGROUP)と混同してはいけません。これらは全く別のエンティティであり、互いに関係していません。
- グローバルサーチオプションの場合、各MPIプロセスは、処理される開始ポイントの詳細レポートを書き出し、そのサマリーをメインプロセスの.outファイルに出力します。生成されるフォルダーの命名法は、シリアルGSOアプローチに類似しています(各フォルダーの末尾は_SP#_UD#で、開始ポイントと固有の設計番号を特定)。
- PARAM,DDMNGRPSをマルチモデル最適化(MMO)ランと併せて使用してはいけません。MMOについては、指定されているnpがモデル数に1を足したものより大きい場合(または各モデルの
npの数がメインファイルで明示的に定義されている場合)は、DDM level 1(タスクベースの並列化)が自動的にアクティブ化されます。MMOのDDM Level 1は単に、過剰なMPIプロセスをモデルに均等に分散します。DDM Level 2並列化は、各モデルに割り当てられているMPIプロセスの数に基づいた各モデルの幾何分割です。詳細については、マルチモデル最適化をご参照ください。
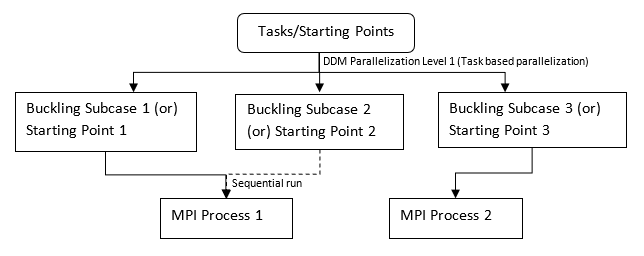
図 6. 3つの座屈サブケースモデル(またはDGLOBALの3つの開始ポイント)の例. DDM Level 1並列化:
-np 2 -ddm、PARAM,DDMNGRPS,MAXを使用(DDM MPIプロセスに順番に幾何分割 / 開始ポイントを割り当て)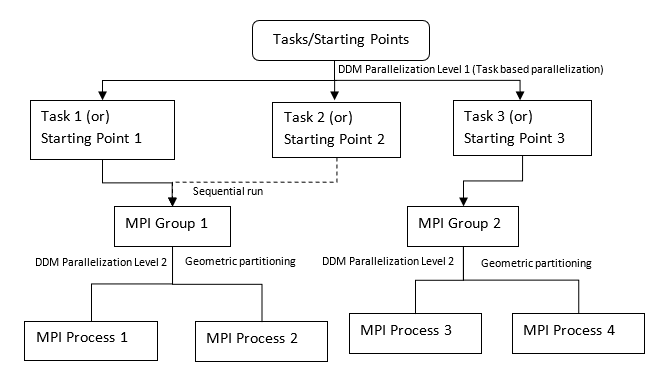
図 7. 3つの座屈サブケースモデル(またはDGLOBALの3つの開始ポイント)の例. ハイブリッドDDM Level 2並列化:
-np 4 -ddm、PARAM,DDMNGRPS,2を使用(DDM MPIグループに順番に3つの座屈サブケース / 開始ポイントを割り当て)続いて、各MPI内で幾何分割が行われます。| 解析タイプ | アクティブ化 | Level 1 | Level 2 | グルーピング |
|---|---|---|---|---|
| 並列グローバルサーチオプション(DDM) | -np # -ddmを使用デフォルトはPARAM,DDMNGRPS,AUTOを用いたハイブリッドDDM PARAM,DDMNGRPS,<ngrps>はオプション |
開始ポイントは並列化される(複数の開始ポイントが1つのMPIプロセスに割り当てられている場合、各開始ポイントはMPIプロセス内で順に解かれる)。 | 開始ポイントは幾何的に分割され、1つのMPIグループにより並列で解かれる(MPIグループが複数のMPIプロセスを有する場合)。 | PARAM,DDMNGRPS,AUTOを介したグルーピングがデフォルト。MPIグループの数を調整する必要がある場合、PARAM,DDMNGRPS,<ngrps>を使用(np> ngrpsである場合、これはLevel 2並列化をアクティブ化し、そこで、複数のMPIプロセスが1つの開始ポイントで稼動可能な場合、一部 / 全ての開始ポイントランの幾何分割が起こる。 |
| 一般的な解析 / 最適化ラン(DDM) | -np # -ddmを使用デフォルトはPARAM,DDMNGRPS,AUTOを用いたハイブリッドDDM PARAM,DDMNGRPS,<ngrps>はオプション |
荷重ケース、荷重周波数(タスクベースの並列化)。サポートされている解析タイプについては表 2を参照のこと。 | 各荷重ケース / 荷重周波数は幾何的に分割され、1つのMPIグループにより並列で解かれる(MPIグループが複数のMPIプロセスを有する場合)。 | PARAM,DDMNGRPS,AUTOを介したグルーピングがデフォルト。MPIグループの数を調整する必要がある場合、PARAM,DDMNGRPS,<ngrps>を使用 上記のシナリオと同様、 |
| DDMでのマルチモデル最適化(MMO) | -np # -mmoを使用PARAM,DDMNGRPSはMMOではサポートされない |
最適化モデルは並列化され、そこで、過剰なMPIプロセス(> モデル数+1)がメインMMOファイル内のモデル(またはメインファイル内の各モデルにつきユーザー定義の-np)に均等に分散される。 |
あらゆるMMO最適化モデルは幾何的に分割され、並列で解かれる(分割の数は、割り当てられているMPIプロセスの数 / npに応じる)。 | グルーピングは、MMOにはサポートされていないため、PARAM,DDMNGRPSを介したグルーピングはなし。ただし、グルーピングは、npのMMOモデルへの自動分配で、またはメインファイルを介した明示的なユーザー入力により、間接的に行われる。 |
DDM Level 2並列化(幾何分割)についてサポートされる解析タイプ
| DDMレベル | サポートされている解析 | ||
|---|---|---|---|
| 領域分割(レベル2) | 線形静解析および最適化 | 非線形静解析 | 線形座屈解析および最適化(SMPにはMUMPSが使用可能) |
| 疲労解析(線形静解析、モーダル過渡解析またはランダム応答解析に基づく) | ノーマルモード(Lanczos法) | モーダル周波数応答(Lanczos法) | |
| モーダル法による初期荷重周波数応答(AMLS/AMSES法) 初期荷重静的サブケースのみが並列化されます。 |
非線形過渡解析 | 直接法による線形過渡解析 | |
| モーダル法による線形過渡解析 | 構造流体-構造相互作用(構造FSI) | マルチモデル最適化(MMO) | |
| 直接法による周波数応答解析(構造、音響、およびMFLUID)(SMPにはMUMPSが使用可能) | 非線形定常熱伝導解析 | 非線形非定常熱伝導解析 | |
| 周期境界条件(PERBC) | |||
反復ソルバーは現時点ではDDMとの使用はサポートされていません。
–ddm実行オプションを使用してDDMをアクティブ化できます。OptiStructでのマルチモデル最適化起動の詳細については、DDMの実行では、MPIプロセス毎にいくつのMPIプロセス(-np)およびスレッド(-nt)を使用すべきですか?をご参照ください。- DDMモードでは、MPIプロセスの種類(マネジャー、メイン、セカンダリなど)は区別されません。すべてのMPIプロセス(領域)は、ワーカーMPIプロセスとみなされます。さらに、複数レベルのハイブリッドDDMは、あらゆるDDMランにとってデフォルトです。したがって、
-np nが指定されている場合、OptiStructはまず、使用可能な-npを順にMPIグループに分割し(PARAM,DDMNGRPS,AUTO)、続いて各MPIグループ内で、そのグループで使用可能なMPIプロセスの数に各グループ内のそのような分割の数が等しい後続の幾何分割が行われます。これらのMPIプロセスは、使用可能性に応じて対応するソケット / マシン上で実行されます。 - ハイブリッド計算がサポートされています。
–ntを使用して、1つのSMPランのMPIプロセス毎のスレッド数(m)を指定できます。場合によっては、ハイブリッドのパフォーマンスが純粋なMPIまたはSMPモードを上回ることもあります(特にブロック構造の場合)。すべてのMPIプロセスのスレッド合計数(n x m)がマシンの物理的なコア数を超えないようにすることも推奨されます。
既知事項
LinuxでのMPI実行は、sshエラーによってエラーが出される場合があります。
Error :/bin/ssh:
$ALTAIR_HOME/altair/hwsolvers/common/python/python3.5/linux64/lib/libcrypto.so.10:
version OPENSSL_1.0.2 not found (required by /bin/ssh)これは、PythonのlibcryptoライブラリとMPIで必要とされるライブラリが競合した場合に発生する可能性があります。これを解決するには、システムからlibcryptoを上記のエラーに記載されている場所にコピーします。システム内では、このライブラリは通常/usr/lib64です。
OptiStruct DDMの起動
OptiStruct DDMを用いて並列プログラムを起動するには、いくつかの方法があります。
OptiStruct DDMを起動する際には、必要に応じて環境変数を設定してください(これは通常、OptiStruct script/GUIではなくOptiStruct実行ファイルを直接実行する場合にのみ必要です)。詳細については、該当するMPIベンダーのマニュアルをご参照ください。OptiStructでは、一般的に使用されるMPIランタイムソフトウェアは、Altair Simulationインストレーションの一部として自動的に含まれます。$ALTAIR_HOME/mpiに各種MPIインストレーションが格納されています。
Linuxマシン
OptiStructスクリプトの使用
領域分割法(DDM)
[optistruct@host1~]$ $ALTAIR_HOME/scripts/optistruct –mpi [MPI_TYPE] –ddm -np [n] -cores [c] [INPUTDECK] [OS_ARGS]
ここで、-mpi: 使用されるMPIインプリメンテーションを選択するためのオプショナルな実行オプション
[MPI_TYPE]は以下が可能:- pl
- IBM Platform-MPI(以前のHP-MPI)の場合
- i
- Intel MPIの場合
-ddm- DDMをアクティブ化するOptiStructの並列化タイプセレクター(DDMがデフォルト)
-np- 実行のためのMPIプロセスの総数を特定するためのオプショナルな実行オプション
[n]- MPIプロセスの総数を指定する整数値(
-np) -cores- 実行のためのコア総数(
-np*-nt)を特定するためのオプショナルな実行オプション [c]- コア総数を指定する整数値(
-cores) [INPUTDECK]- 入力デックのファイル名
[OS_ARGS]- OptiStructへの引数のリスト(オプション。詳細については、実行オプションをご参照ください)。
- コマンド行オプション
-testmpiを追加すると、MPIインストレーション、セットアップ、ライブラリパスなどが正しいかどうかを検証する小さなプログラムが実行されます。 - OptiStruct DDMは、Compute Console (ACC) GUIを使って起動することも可能です。(Compute Console (ACC)をご参照ください)。
- 推奨はされませんが、GUI / ソルバースクリプトを使用せずにOptiStruct DDMを起動することも可能です。FAQセクション内のDDMの実行では、MPIプロセス毎にいくつのMPIプロセス(-np)およびスレッド(-nt)を使用すべきですか?をご参照ください。
- オプションのコマンド行オプション
–mpipath PATHを追加すると、MPIインストレーションが現在の探索パスに含まれていなかったり、複数のMPIがインストールされている場合に、MPIインストレーションを見つけることができます。 - SPMD実行オプション(
-mmo/-ddm/-fso)が指定されていない場合、DDMがデフォルトで実行されます。
Windowsマシン
OptiStructスクリプトの使用
領域分割法(DDM)
[optistruct@host1~]$ $ALTAIR_HOME/hwsolvers/scripts/optistruct.bat –mpi [MPI_TYPE] –ddm -np [n] -cores [c] [INPUTDECK] [OS_ARGS]
ここで、-mpi: 使用されるMPIインプリメンテーションを選択するためのオプショナルな実行オプション。
[MPI_TYPE]は以下が可能:- pl
- IBM Platform-MPI(以前のHP-MPI)の場合
- i
- Intel MPIの場合
-ddm- DDMをアクティブ化するOptiStructの並列化タイプセレクター(DDMがデフォルト)
-np- 実行のためのMPIプロセスの総数を特定するためのオプショナルな実行オプション
[n]- MPIプロセスの総数を指定する整数値(
-np) -cores- 実行のためのコア総数(
-np*-nt)を特定するためのオプショナルな実行オプション [c]- コア総数を指定する整数値(
-cores) [INPUTDECK]- 入力デックのファイル名
[OS_ARGS]- OptiStructへの引数のリスト(オプション。詳細については、実行オプションをご参照ください)。
- コマンド行オプション
-testmpiを追加すると、MPIインストレーション、セットアップ、ライブラリパスなどが正しいかどうかを検証する小さなプログラムが実行されます。 - OptiStruct DDMは、Compute Console (ACC) GUIを使って起動することも可能です。(Compute Console (ACC)をご参照ください)。
- GUI / ソルバースクリプトを使用せずにOptiStruct DDMを起動することも可能です。FAQセクション内のDDMの実行では、MPIプロセス毎にいくつのMPIプロセス(-np)およびスレッド(-nt)を使用すべきですか?をご参照ください。
- オプションのコマンド行オプション
–mpipath PATHを追加すると、MPIインストレーションが現在の探索パスに含まれていなかったり、複数のMPIがインストールされている場合に、MPIインストレーションを見つけることができます。 - SPMD実行オプション(
-mmo/ -ddm /-fso)が指定されていない場合、DDMがデフォルトで実行されます。
実行ファイルへのダイレクトコールを使用したLinuxマシン
OptiStruct実行ファイルを直接実行する代わりに、OptiStructスクリプト($ALTAIR_HOME/scripts/optistruct)またはOptiStruct GUI(Compute Console (ACC))を使用することが推奨されます。ただし、特定の実行について実行ファイルの直接使用が避けられない場合は、実行に先駆けてまず、対応する環境変数、RADFLEXライセンス環境変数、ライブラリパス変数などを定義することが重要です。
シングルホスト(IBM Platform-MPIおよびIntel MPI用)の場合
領域分割法(DDM)
[optistruct@host1~]$ mpirun -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS] -ddmmode
マルチモデル最適化(MMO)
[optistruct@host1~]$ mpirun -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS] -mmomode
フェイルセーフトポロジー最適化(FSO)
[optistruct@host1~]$ mpirun -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS] -fsomode
- optistruct_spmd
- OptiStruct SPMDバイナリ
[n]- プロセッサ数
[INPUTDECK]- 入力デックのファイル名
[OS_ARGS]-ddmmode/-mmomode/-fsomode以外のOptiStructへの引数をリスト(オプション。詳細については、実行オプションを参照のこと)注: 実行ファイルへのダイレクトコールを使用してOptiStruct SPMDを実行するには、上に示した追加のコマンド行オプション-ddmmode/-mmomode/-fsomodeが必要です。これらの実行オプションのいずれかが使用されないと、並列化は行われず、プログラム全体が各ノードで実行されます。
Linuxクラスタ(IBM Platform-MPI用)の場合
領域分割法(DDM)
[optistruct@host1~]$ mpirun –f [appfile]
ここで、appfile contains:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] -ddmmode
マルチモデル最適化(MMO)
[optistruct@host1~]$ mpirun –f [appfile]
ここで、appfile contains:
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] -mmomode
フェイルセーフトポロジー最適化(FSO)
[optistruct@host1~]$ mpirun –f [appfile]
ここで、appfile contains:
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] -fsomode
[appfile]- [プロセスのカウントとプログラムのリストを含んだテキストファイル
- optistruct_spmd
- OptiStruct SPMDバイナリ
-ddmmode/-mmomode/-fsomodeが必要です。これらのオプションのいずれかが使用されないと、並列化は行われず、プログラム全体が各ノードで実行されます。c1およびc2と命名)[optistruct@host1~]$ cat appfile
-h c1 –np 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] -ddmmode
-h c2 –np 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] –ddmmodeLinuxクラスタ(Intel-MPI用)の場合
領域分割法(DDM)
[optistruct@host1~]$ mpirun –f [hostfile] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS] -ddmmode
マルチモデル最適化(MMO)
[optistruct@host1~]$ mpirun –f [hostfile] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS] -mmomode
フェイルセーフトポロジー最適化(FSO)
[optistruct@host1~]$ mpirun –f [hostfile] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS] -fsomode
- optistruct_spmd
- OptiStruct SPMDバイナリ
[hostfile]- ホスト名を含むテキストファイル
[host i]- 1つのホストに必要なのは1つのラインのみです。
- 実行ファイルへのダイレクトコールを使用してOptiStruct SPMDを実行するには、上に示した追加のコマンド行オプション
-ddmmode/-mmomode/-fsomodeが必要です。これらのオプションのいずれかが使用されないと、並列化は行われず、プログラム全体が各ノードで実行されます。
c1、c2と命名)[optistruct@host1~]$ cat hostfile
c1
c2実行ファイルへのダイレクトコールを使用したWindowsマシン
シングルホスト(IBM Platform-MPI用)の場合
領域分割法(DDM)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS] -ddmmode
マルチモデル最適化(MMO)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS] -mmomode
フェイルセーフトポロジー最適化(FSO)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS] -fsomode
- optistruct_spmd
- OptiStruct SPMDバイナリ
[n]- プロセッサ数
[INPUTDECK]- 入力デックのファイル名
[OS_ARGS]-ddmmode/-mmomode/-fsomode以外のOptiStructへの引数をリスト(オプション。詳細については、実行オプションを参照のこと)注: 実行ファイルへのダイレクトコールを使用してOptiStruct SPMDを実行するには、上に示した追加のコマンド行オプション-ddmmode/-mmomode/-fsomodeが必要です。これらの実行オプションのいずれかが使用されないと、並列化は行われず、プログラム全体が各ノードで実行されます。
シングルホスト(Intel-MPI用)の場合
領域分割法(DDM)
[optistruct@host1~]$ mpiexec -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS] -ddmmode
マルチモデル最適化(MMO)
[optistruct@host1~]$ mpiexec -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS] -mmomode
フェイルセーフトポロジー最適化(FSO)
optistruct@host1~]$ mpiexec -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS] -fsomode
- optistruct_spmd
- OptiStruct SPMDバイナリ
[n]- プロセッサ数
[INPUTDECK]- 入力デックのファイル名
[OS_ARGS]-ddmmode/-mmomode/-fsomode以外のOptiStructへの引数をリスト(オプション。詳細については、実行オプションを参照のこと)
Windowsマルチホスト(IBM Platform-MPI用)の場合
領域分割法(DDM)
[optistruct@host1~]$ mpirun –f [hostfile]
ここで、appfileは以下を含む:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -ddmmode
マルチモデル最適化(MMO)
[optistruct@host1~]$ mpirun –f [hostfile]
ここで、appfileは以下を含む:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -mmomode
フェイルセーフトポロジー最適化(FSO)
[optistruct@host1~]$ mpirun –f [hostfile]
ここで、appfileは以下を含む:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -fsommode
[appfile]は、プロセスのカウントとプログラムのリストを含んだテキストファイル。-ddmmode/-mmomode/-fsomodeが必要です。これらの実行オプションのいずれかが使用されないと、並列化は行われず、プログラム全体が各ノードで実行されます。c1およびc2と命名)optistruct@host1~]$ cat hostfile
-host c1 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -mpimode
-host c2 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] –mpimodeWindowsマルチホスト(Intel-MPI用)の場合
領域分割法(DDM)
[optistruct@host1~]$ mpiexec –configfile [config_file]
ここで、config_fileは以下を含む:
optistruct@host1~]$ cat config_file
-host [host i] –n [np] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] –ddmmode
マルチモデル最適化(MMO)
[optistruct@host1~]$ mpiexec –configfile [config_file]
ここで、config_fileは以下を含む:
optistruct@host1~]$ cat config_file
-host [host i] –n [np] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -mmomode
フェイルセーフトポロジー最適化(FSO)
[optistruct@host1~]$ mpiexec –configfile [config_file]
ここで、config_fileは以下を含む:
optistruct@host1~]$ cat config_file
-host [host i] –n [np] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -fso
[config_file]は、各ホスト用のコマンドを含むテキストファイル。- 1つのホストに必要なのは1つのラインのみです。
- 実行ファイルへのダイレクトコールを使用してOptiStruct SPMDを実行するには、上に示した追加のコマンド行オプション
-ddmmode/-mmomode/-fsomodeが必要です。これらのオプションのいずれかが使用されないと、並列化は行われず、プログラム全体が各ノードで実行されます。
c1およびc2と命名)optistruct@host1~]$ cat config_file
-host c1 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -ddmmode
-host c2 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] –ddmmode